Como estruturar o output de agentes quando você processa centenas de entradas ao mesmo tempo
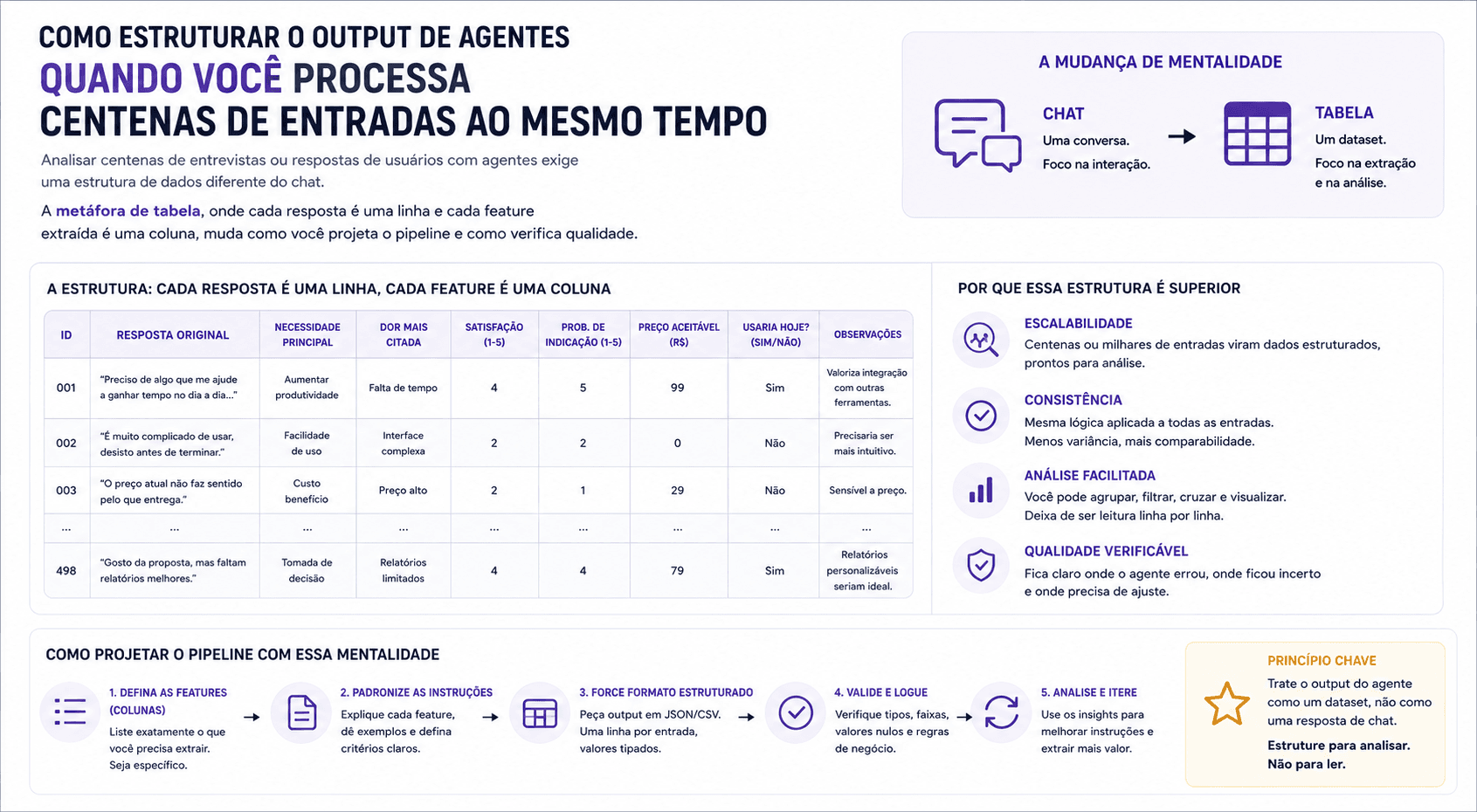
Como estruturar o output de agentes quando você processa centenas de entradas ao mesmo tempo
Existe uma diferença fundamental entre construir um agente que responde uma pergunta de cada vez e construir um sistema que processa centenas de respostas, entrevistas, ou feedbacks em paralelo. A diferença não está só na escala. Está na estrutura de dados que o sistema produz.
O Listen, uma plataforma que usa agentes para analisar entrevistas e surveys, usa uma metáfora que clarifica isso: cada resposta de usuário é uma linha de uma tabela. Cada feature que o agente extrai é uma coluna. O agente não produz um relatório por conversa; ele popula uma tabela onde cada nova análise adiciona uma coluna.
Por que a metáfora de tabela importa
Num chatbot ou num sistema de QA, o output é texto livre. Cada resposta é única e não se relaciona estruturalmente com as outras. Para análise, você precisa ler tudo e sintetizar manualmente.
Na estrutura de tabela, o agente extrai features consistentes de cada resposta: sentimento, temas principais, categorias de objeção, intensidade emocional, elementos específicos mencionados. Cada feature é uma coluna, e você pode agregar, filtrar, e comparar entre respostas de formas que texto livre não permite.
A consequência prática é que um agente pode criar novas colunas dinamicamente: se você quer saber o que os usuários pensam sobre preço, você cria uma coluna "mencionou preço" e o agente passa por todas as linhas e preenche. Isso é muito mais rápido e consistente do que reler as transcrições manualmente.
Como escalar para centenas de inputs
Quando você processa 500 entrevistas, o bottleneck não é a qualidade do modelo. É a latência de cada chamada individual.
O Listen resolve isso com o padrão que ficou claro em uma entrevista com o CTO: quando uma operação precisa ser aplicada a muitas entradas, o sistema spawna 500 agentes em paralelo, cada um processando uma resposta, e depois agrega os resultados de forma estruturada. Uma única chamada de alto nível ativa essa paralelização internamente.
Isso muda como você precisa pensar sobre error handling. Com um agente único, uma falha é simples de detectar e corrigir. Com 500 agentes rodando em paralelo, você precisa de mecanismos para identificar quais falharam, retentativas seletivas, e agregação que é robusta a resultados faltantes.
Reviewer como sub-agente de qualidade
O segundo componente que aparece nesse tipo de sistema é um agente revisor. No Listen, um sub-agente separado verifica os outputs do agente principal antes de usar no relatório final. Esse revisor tem um único papel: saber o que um bom output parece e rejeitar o que não parece.
Isso resolve um problema sutil em análise de grande volume. Quando você processa centenas de respostas, a proporção de erros individuais pode ser baixa, mas o volume absoluto de erros pode ser alto o suficiente para comprometer o relatório final. Um revisor que roda assincronamente pega esses casos antes de chegarem no produto final.
A mesma arquitetura serve como sistema de eval em produção: o revisor que foi treinado para identificar outputs problemáticos pode ser rodado no pipeline ao vivo para monitorar qualidade ao longo do tempo.
Como isso se relaciona com sistemas empresariais de processamento em volume
No Nexus ZDT, o pipeline de automação de RH processa requisições de múltiplos funcionários de múltiplas empresas em paralelo. A estrutura de cada requisição tem campos que precisam ser extraídos e validados: tipo de solicitação, dados do funcionário, período, aprovações necessárias. Cada requisição é essencialmente uma linha de uma tabela com colunas estruturadas.
O que o padrão do Listen revela é que para esse tipo de processamento em volume, a estrutura do output precisa ser pensada como dado, não como texto. A diferença entre "o agente analisou essa entrevista" e "o agente preencheu 15 colunas de features para essa entrevista" é a diferença entre um output que precisa de interpretação humana e um output que pode ser consultado, filtrado, e agregado diretamente.
O que o processamento multimodal adiciona
Uma camada adicional que o Listen implementa é extração de sinal emocional de vídeo e áudio, não só de texto. Para entrevistas gravadas, o tom de voz, a hesitação, a emoção visível no vídeo carregam informação que a transcrição não captura.
Isso exige modelos de visão-linguagem e análise de áudio como parte do pipeline, não só processamento de texto. O resultado é uma coluna de "intensidade emocional" ou "indicadores de frustração" que não existiria num sistema puramente textual.
Para quais tipos de análise você ainda usa processos manuais porque os agentes que você tem não produzem output estruturado o suficiente para automatizar a etapa seguinte?
Assine a Newsletter
Receba conteúdo exclusivo sobre IA, LLMs e desenvolvimento em produção diretamente no seu email.
Sem spam. Cancele quando quiser.
Posts Relacionados
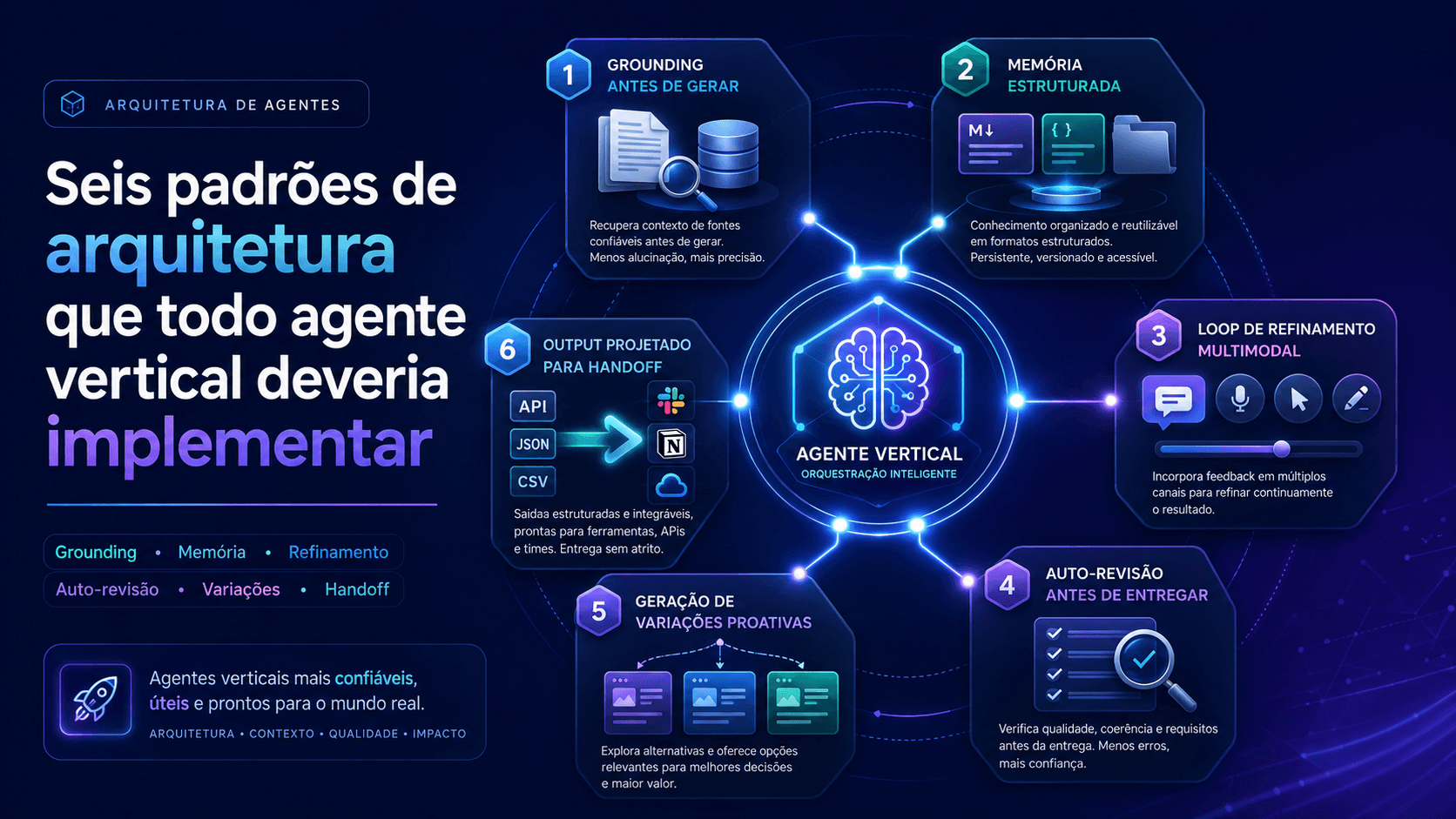
Seis padrões de arquitetura que todo agente vertical deveria implementar
O Claude Design virou referência não pelo que ele produz, mas por como ele foi construído. Seis padrões arquiteturais que aparecem nesse sistema podem ser extraídos e aplicados em qualquer agente vertical: jurídico, comercial, de RH, de operações.
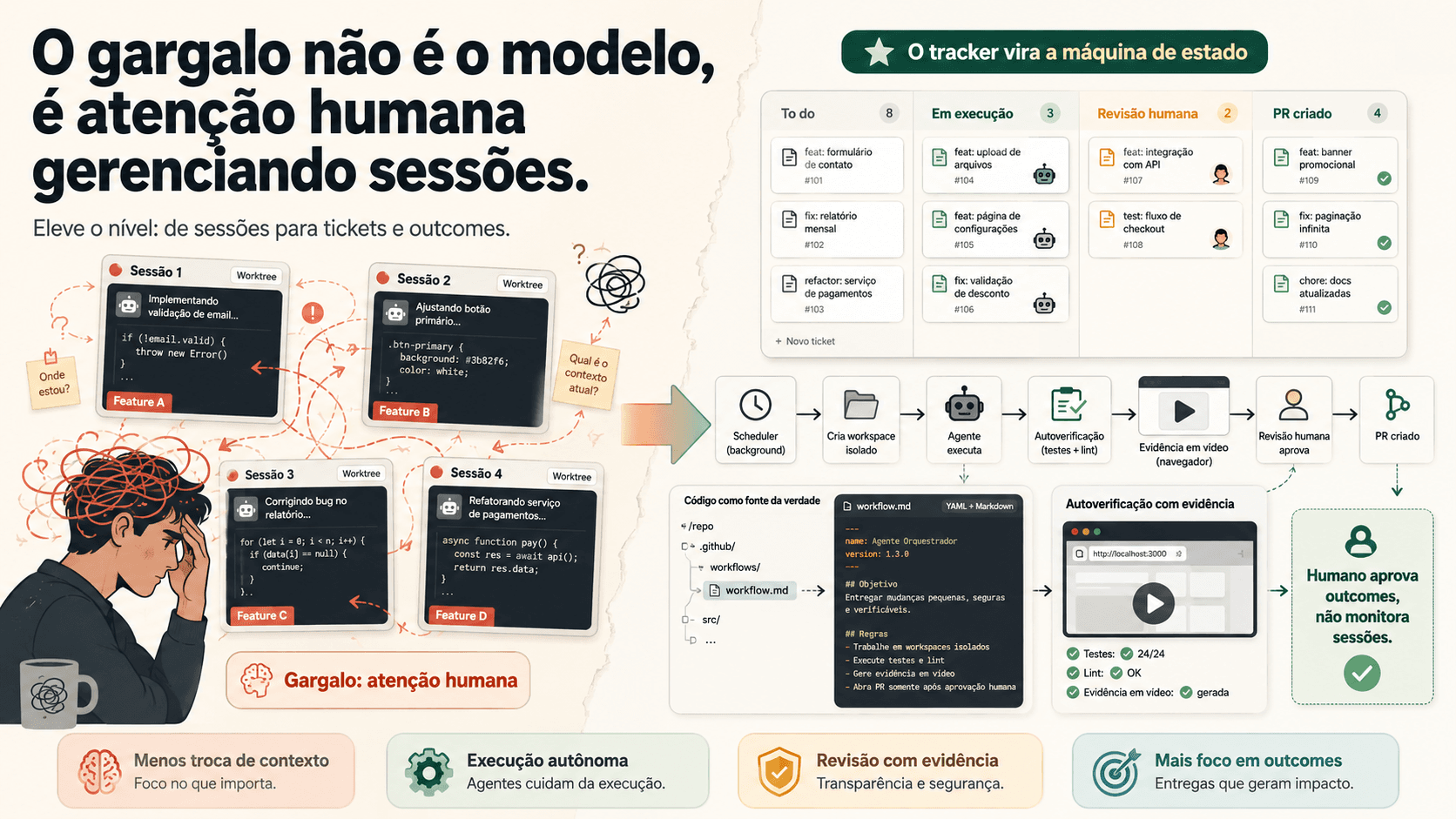
O gargalo não é o modelo, é atenção humana gerenciando sessões
O teto de quanto você consegue extrair de agentes de código não é mais capacidade do modelo. É quanto contexto humano você consegue manter ativo ao mesmo tempo. A mudança de paradigma é de gerenciar sessões para gerenciar resultados.
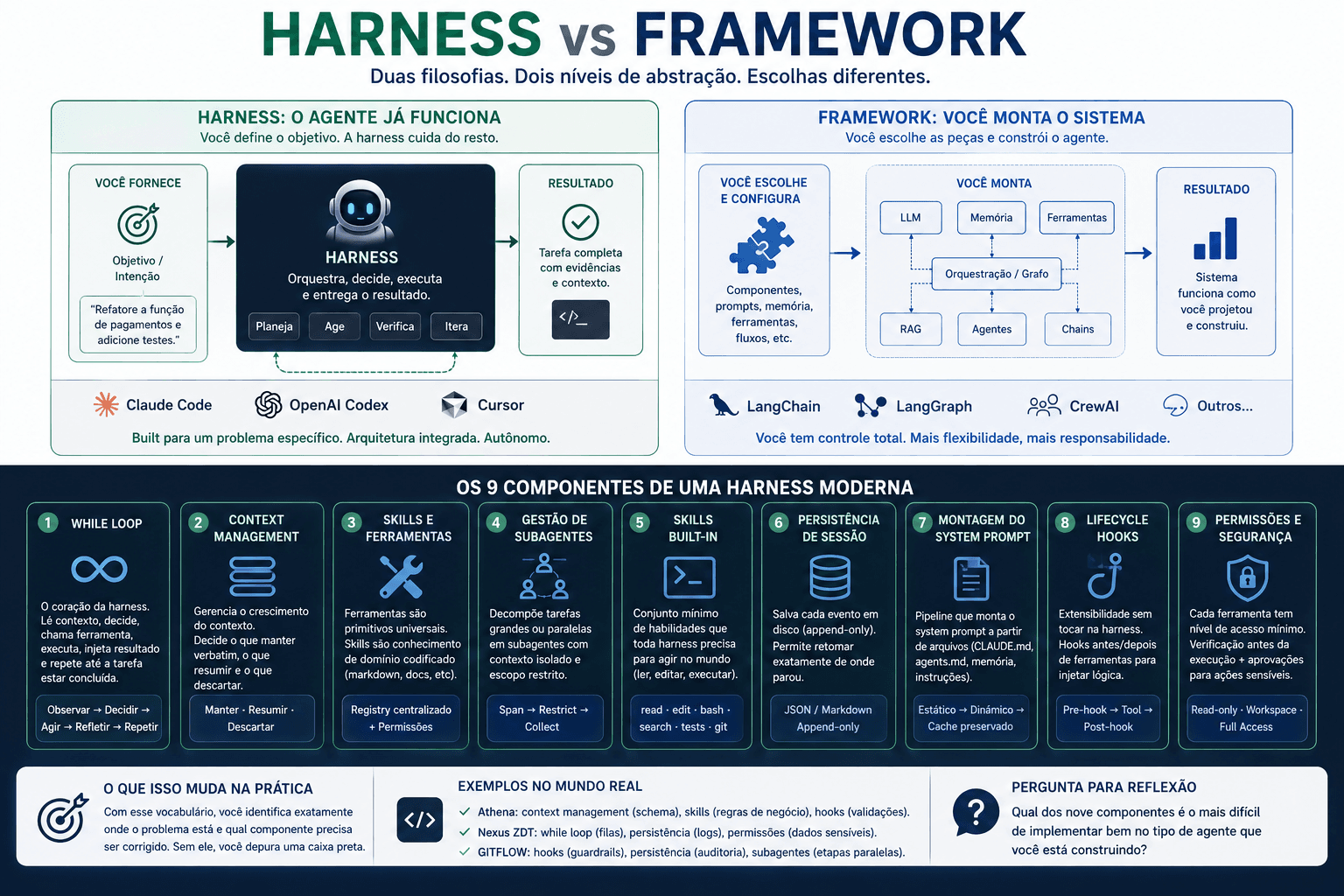
O que é uma harness e por que a distinção com framework importa
Harness e framework não são sinônimos. Um framework te dá peças para montar um agente. Uma harness já é o agente, e você fornece o objetivo. Entender essa distinção muda o que você escolhe construir e por quê.