Deixar o agente encontrar os parâmetros certos: o loop de auto-otimização
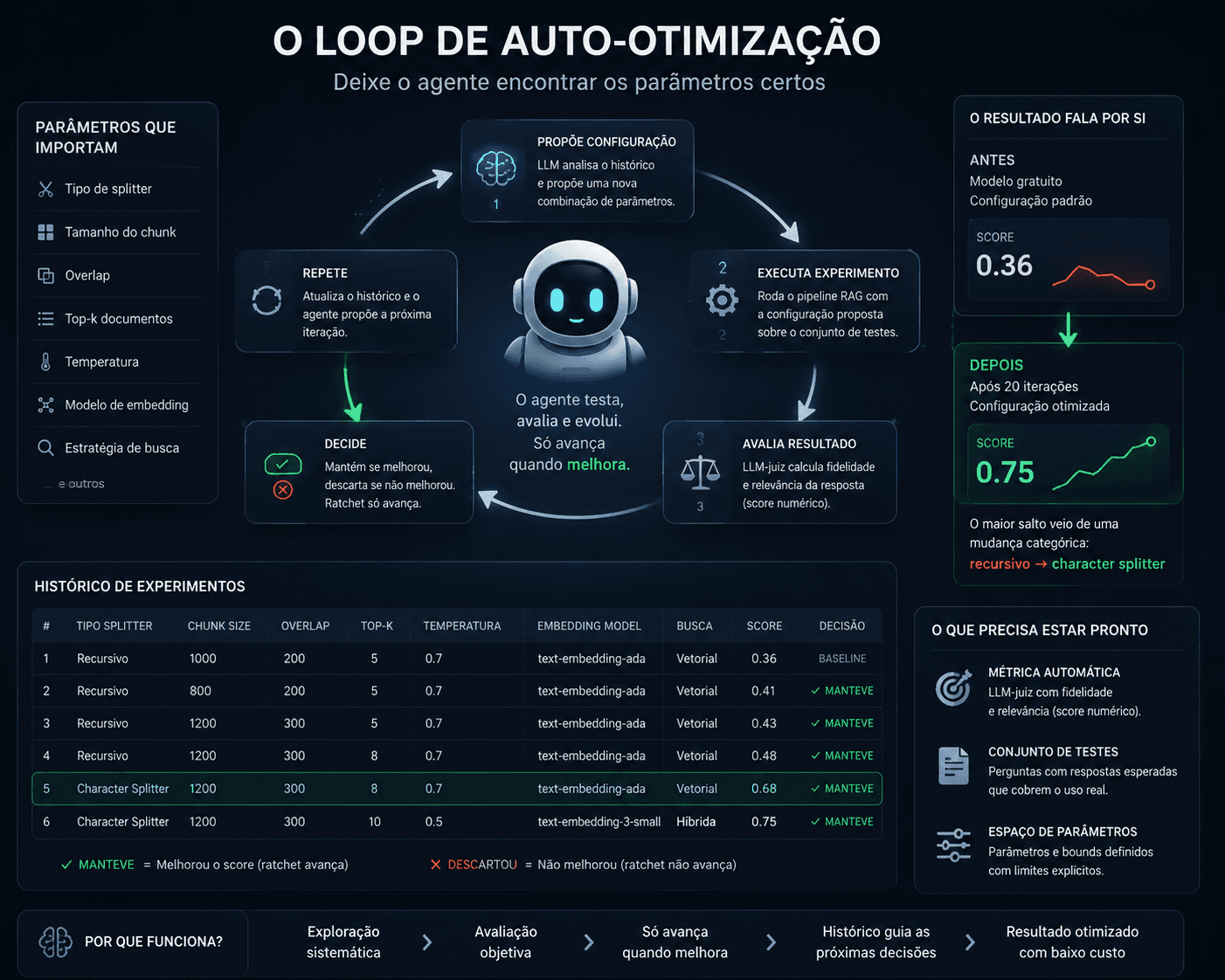
Deixar o agente encontrar os parâmetros certos: o loop de auto-otimização
Um pipeline RAG tem pelo menos meia dúzia de parâmetros que afetam a qualidade da resposta de forma significativa: tipo de splitter, tamanho do chunk, overlap, top-k de documentos recuperados, temperatura, modelo de embedding, estratégia de busca. A maioria dos times testa esses parâmetros de forma manual, que na prática significa testar poucos, com viés para os que parecem mais óbvios, e parar quando o resultado parece aceitável.
O problema não é que os engenheiros são preguiçosos. É que o espaço de combinações é grande o suficiente para que exploração manual seja estatisticamente ineficiente. Você não vai testar 200 combinações na mão.
O padrão do auto-research
A ideia por trás do Auto-Research, o projeto do Karpathy que gerou muita conversa recentemente, é simples: qualquer sistema com parâmetros ajustáveis e uma métrica mensurável pode ser otimizado por um loop autônomo. O loop é: propõe uma configuração nova, roda o experimento, avalia o resultado, mantém se melhorou, descarta se não melhorou, repete.
O que torna esse padrão poderoso é a parte do "descarta se não melhorou". Não é uma busca aleatória. É um processo de ratchet: o estado do sistema só avança quando há melhora verificada. Cada experimento é um commit com resultado medido. O histórico de experimentos fica visível para o LLM que propõe a próxima configuração, que pode raciocinar sobre o que está e o que não está funcionando.
Aplicado a RAG, o loop funciona assim: um orchestrador lê o histórico de experimentos anteriores, chama um LLM para propor uma nova configuração baseada no que já foi testado, executa o pipeline RAG com essa configuração sobre uma base de documentos e um conjunto de perguntas pré-carregadas, avalia as respostas com LLM como juiz calculando fidelidade e relevância, e decide se mantém ou descarta.
O que a prática ensina
Em um experimento com 20 iterações sobre documentos médicos, o pipeline saiu de score 0.36 com modelo gratuito e configuração padrão para 0.75. O maior salto aconteceu não numa mudança de parâmetro numérico, mas numa mudança categórica: a troca do tipo de splitter de recursivo para character splitter. O sistema identificou essa oportunidade depois de esgotar o espaço de parâmetros numéricos.
Isso revela algo sobre como o LLM-pesquisador se comporta: ele tende a explorar o espaço numérico antes de fazer mudanças categóricas. E quando faz a mudança categórica que desbloqueia um salto, ela costuma ser a maior melhoria do ciclo.
O resultado que levaria horas de experimentação manual aconteceu em uma noite, com custo baixo de tokens usando modelos baratos para os experimentos e um modelo mais capaz só para propor as próximas configurações.
O que precisa estar pronto
Para que esse loop funcione, três coisas precisam estar definidas antes de rodar:
A métrica de avaliação tem que ser automática e numérica. Um LLM como juiz que calcula fidelidade e relevância da resposta em relação à pergunta e ao contexto recuperado é o que permite comparar experimentos com objetividade. Se você não tem um conjunto de pares pergunta-resposta esperada, você não tem métrica, e sem métrica não tem como avaliar.
O conjunto de testes precisa ser preparado com cuidado. Vinte perguntas com respostas esperadas derivadas dos documentos que o sistema vai consultar. Essas perguntas precisam cobrir os tipos de consulta que o sistema vai receber em produção. Usar um modelo bom para gerar as perguntas e verificar manualmente é o processo razoável.
O espaço de parâmetros precisa ser definido com bounds explícitos. O LLM-pesquisador precisa saber quais parâmetros pode variar e dentro de quais intervalos. Sem isso, ele vai sugerir combinações não testáveis ou explorar infinitamente sem convergir.
Por que isso é relevante além do RAG
O padrão do loop de auto-otimização não é específico para RAG. Qualquer sistema onde você tem parâmetros ajustáveis e uma forma de medir o resultado pode usar a mesma abordagem.
No caso do Athena, por exemplo, os parâmetros que afetam a qualidade das queries geradas incluem como o contexto de schema é estruturado, quantos exemplos de queries similares são incluídos, e como as regras de negócio específicas de cada empresa são formatadas. Hoje esse ajuste é manual. Um loop que propõe variações de contexto, avalia a correção das queries geradas e mantém o que melhora é tecnicamente viável com a mesma lógica.
O que o Auto-RAG Optimizer demonstra é que a diferença entre o estado inicial de um pipeline e o estado otimizado não é conhecimento especializado aplicado manualmente. É capacidade de experimentação sistemática com uma métrica clara. Isso pode ser delegado.
Qual parâmetro do seu pipeline de AI você nunca testou sistematicamente porque seria muito trabalhoso fazer na mão?
Assine a Newsletter
Receba conteúdo exclusivo sobre IA, LLMs e desenvolvimento em produção diretamente no seu email.
Sem spam. Cancele quando quiser.
Posts Relacionados
Seis padrões de arquitetura que todo agente vertical deveria implementar
O Claude Design virou referência não pelo que ele produz, mas por como ele foi construído. Seis padrões arquiteturais que aparecem nesse sistema podem ser extraídos e aplicados em qualquer agente vertical: jurídico, comercial, de RH, de operações.
Prompt não é instrução. Contexto é o recurso que o modelo usa para raciocinar
A maioria das pessoas ainda trata prompt como uma instrução que você dá ao modelo. A mudança de perspectiva que importa é perceber que contexto é o recurso escasso, e o que você injeta nele determina o teto de qualidade do que sai.
O que é uma harness e por que a distinção com framework importa
Harness e framework não são sinônimos. Um framework te dá peças para montar um agente. Uma harness já é o agente, e você fornece o objetivo. Entender essa distinção muda o que você escolhe construir e por quê.