GraphRAG: quando RAG vetorial começa a falhar
GraphRAG: quando RAG vetorial começa a falhar
Tenho uma afirmação direta: RAG vetorial tem dois problemas fundamentais que não são de escala, são de design. E a maioria dos sistemas que usa RAG em produção vai encontrar um deles em algum momento.
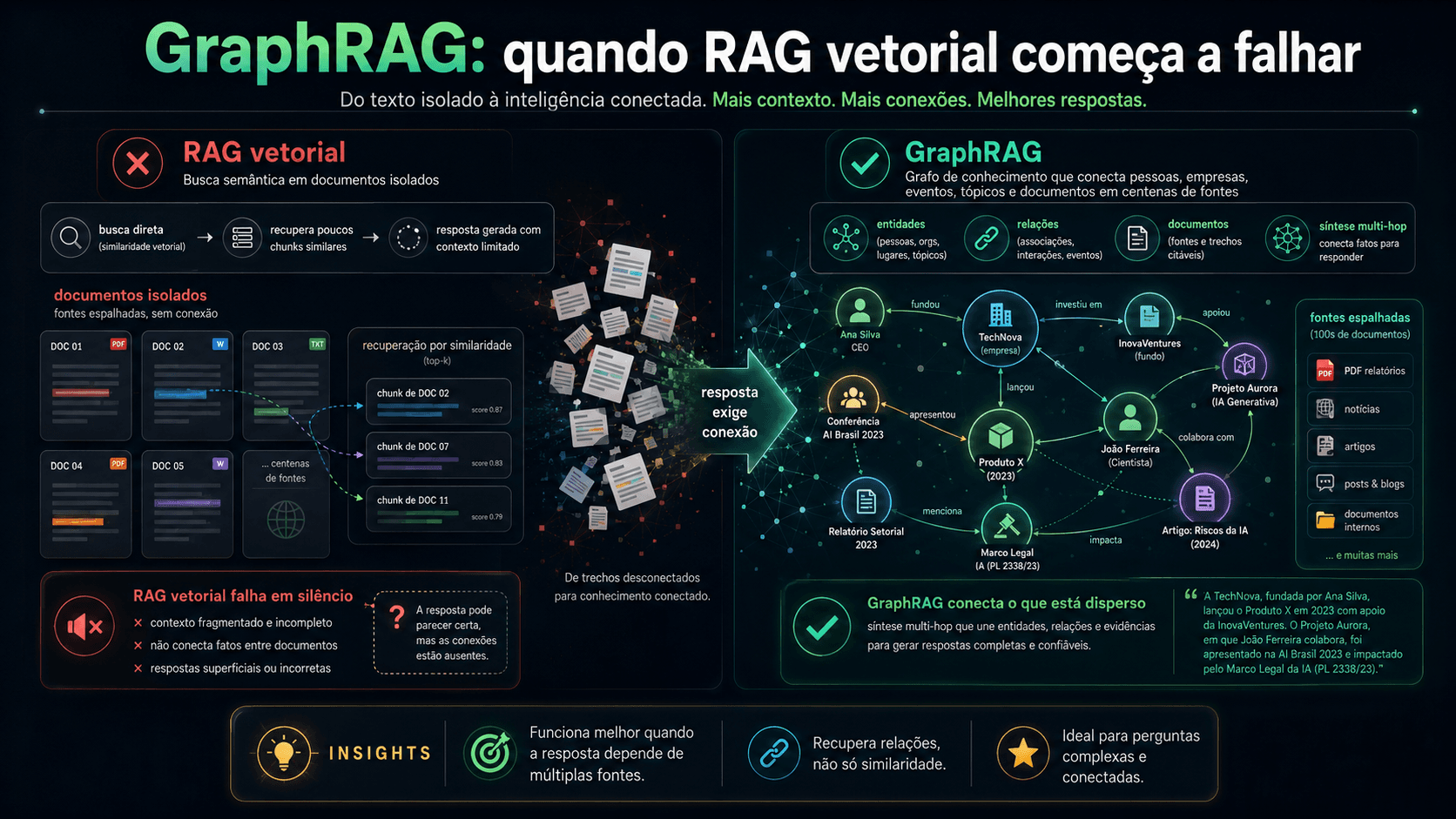
O primeiro é que cada chunk existe isolado. Depois que você divide os documentos e gera os embeddings, cada fragmento de texto vive sozinho no espaço vetorial. O sistema recupera o que é semanticamente próximo da pergunta, mas não tem como saber como esse fragmento se relaciona com o fragmento ao lado dele, nem com documentos de outras fontes.
O segundo é que o sistema não raciocina entre documentos. Se a resposta para uma pergunta exige conectar três informações espalhadas em fontes diferentes, o RAG vetorial pode trazer todas as três separadamente, mas não tem mecanismo para sintetizar a conexão entre elas antes de passar para o modelo.
Quando isso importa na prática
No Athena, o agente de consultas no TOTVS Protheus que atende múltiplas empresas, o desafio original era exatamente esse. O sistema precisava entender a relação entre módulos diferentes do ERP: como as regras do RH se conectam com os campos da tabela de folha de pagamento, como as convenções de cada empresa afetam os filtros que devem ser aplicados.
A solução que desenvolvemos usou chunking por delimitador semântico customizado, onde cada bloco continha uma query SQL completa com todas as regras de negócio e tabelas envolvidas. Isso criou uma forma rudimentar de preservar as relações dentro de cada contexto de consulta. Mas ainda era limitado para perguntas que cruzavam múltiplos contextos.
GraphRAG ataca o problema de uma forma estruturalmente diferente.
A ideia central do GraphRAG
Em vez de tratar documentos como bags of chunks, GraphRAG usa um LLM para extrair entidades e relações de cada documento durante a indexação. Essas entidades viram nós num grafo de conhecimento. As relações viram arestas. O resultado é uma estrutura que captura explicitamente como as informações se conectam entre fontes diferentes.
Depois disso, um algoritmo de detecção de comunidade agrupa entidades relacionadas em clusters. Para cada cluster, um LLM gera um resumo. É esse conjunto de resumos de comunidades que é consultado na hora de responder uma pergunta, não os chunks brutos.
A consequência prática: perguntas que exigem síntese ampla, "quais são os principais argumentos legais nesse conjunto de documentos?", "quais empresas estão conectadas nessa disputa?", podem ser respondidas com muito mais precisão porque o sistema já tem uma representação estrutural das conexões.
O que isso não é
GraphRAG não substitui RAG vetorial. É uma ferramenta diferente para um tipo diferente de problema.
Para perguntas diretas com resposta localizada, "quando essa lei foi aprovada?", "quem assinou esse contrato?", RAG vetorial é mais rápido, mais barato e suficiente. O grafo adiciona custo de construção e de consulta que não se justifica quando o problema é simples.
GraphRAG faz sentido quando você tem muitos documentos densamente interconectados, quando as perguntas exigem raciocínio entre múltiplas fontes, e quando transparência na origem da resposta é importante. Domínios legais, de pesquisa, e análise de mercado são os casos mais evidentes.
O que fica claro depois de construir um
Dois pontos que mudaram minha perspectiva depois de implementar:
O primeiro é a importância da ontologia. Definir quais tipos de entidade e quais tipos de relação o sistema vai extrair não é detalhe de implementação. É a decisão arquitetural mais importante. Uma ontologia frouxa gera grafos poluídos onde "OpenAI" e "Open AI" são entidades diferentes, onde relações genéricas como "menciona" substituem relações específicas como "processa na justiça". O grafo reflete a qualidade das definições que você deu para o extrator.
O segundo é o custo de indexação. Construir um grafo a partir de centenas de documentos exige muitas chamadas de LLM. Isso precisa estar no cálculo desde o início. A extração pode ser feita com modelos menores e baratos, o que alivia o custo, mas ainda assim não é gratuita.
Onde isso fica interessante para sistemas empresariais
O padrão que GraphRAG estabelece, construir uma representação estrutural das relações antes de responder perguntas, não precisa ser limitado a documentos textuais.
O que me parece mais promissor é aplicar a mesma lógica a bases de dados de processos empresariais. Um grafo de entidades e relações construído a partir de dados operacionais, onde funcionários, aprovações, regras de negócio e histórico de exceções são nós com arestas explícitas, seria um contexto muito mais rico para um agente de automação do que um prompt com documentação estática.
Qual tipo de pergunta no seu domínio exigiria conectar informação entre múltiplas fontes de uma forma que RAG vetorial não consegue responder bem?
Assine a Newsletter
Receba conteúdo exclusivo sobre IA, LLMs e desenvolvimento em produção diretamente no seu email.
Sem spam. Cancele quando quiser.
Posts Relacionados
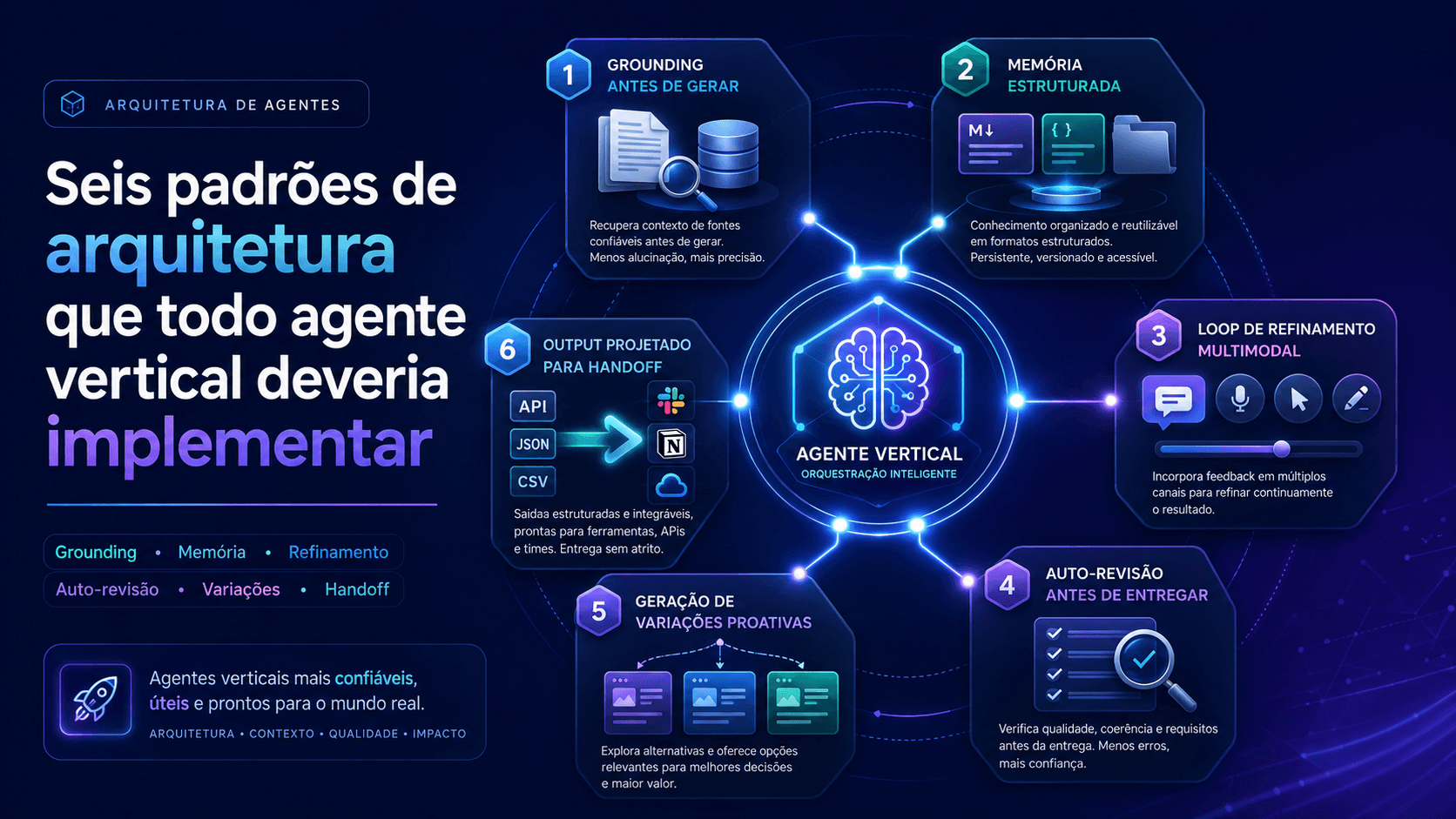
Seis padrões de arquitetura que todo agente vertical deveria implementar
O Claude Design virou referência não pelo que ele produz, mas por como ele foi construído. Seis padrões arquiteturais que aparecem nesse sistema podem ser extraídos e aplicados em qualquer agente vertical: jurídico, comercial, de RH, de operações.
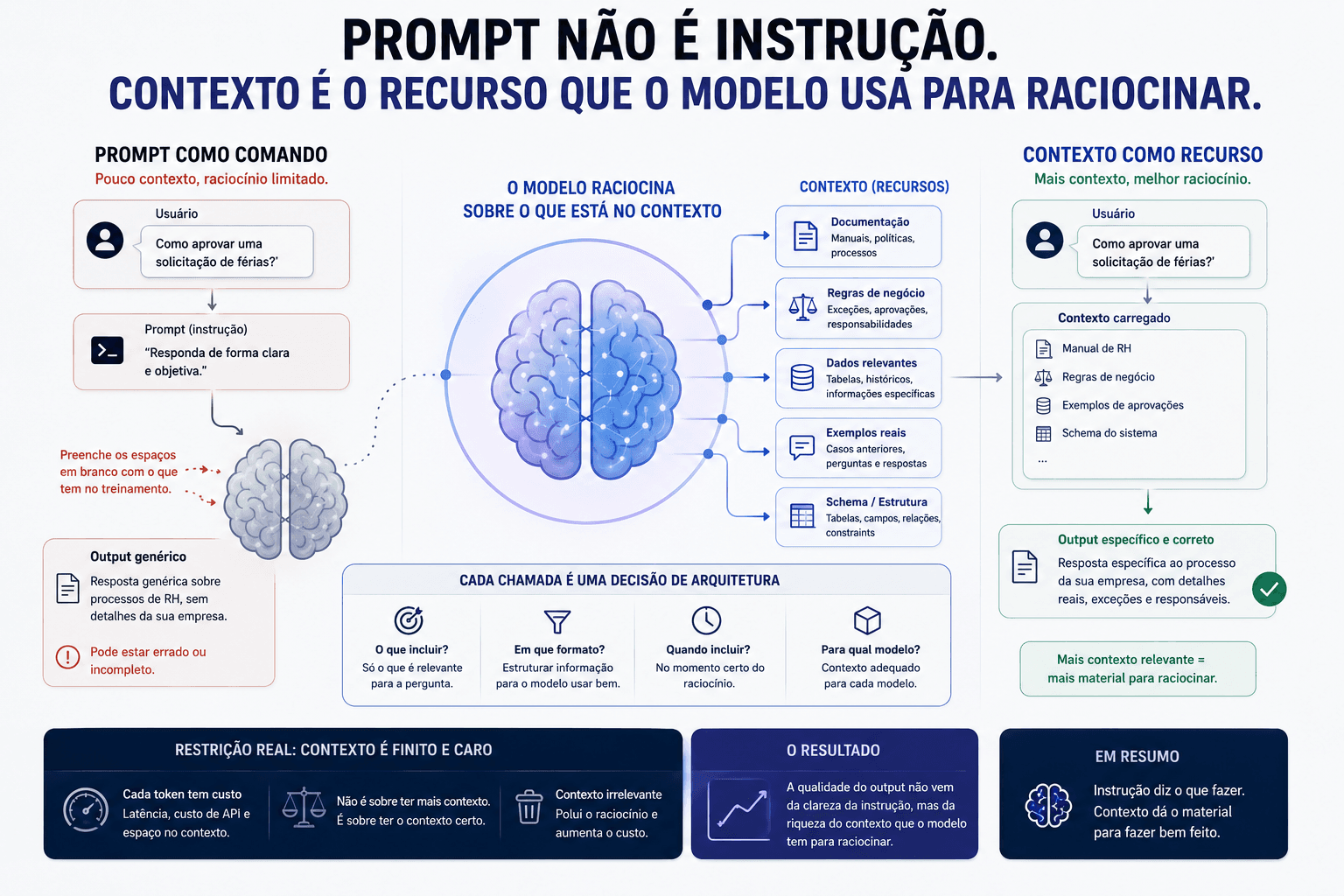
Prompt não é instrução. Contexto é o recurso que o modelo usa para raciocinar
A maioria das pessoas ainda trata prompt como uma instrução que você dá ao modelo. A mudança de perspectiva que importa é perceber que contexto é o recurso escasso, e o que você injeta nele determina o teto de qualidade do que sai.
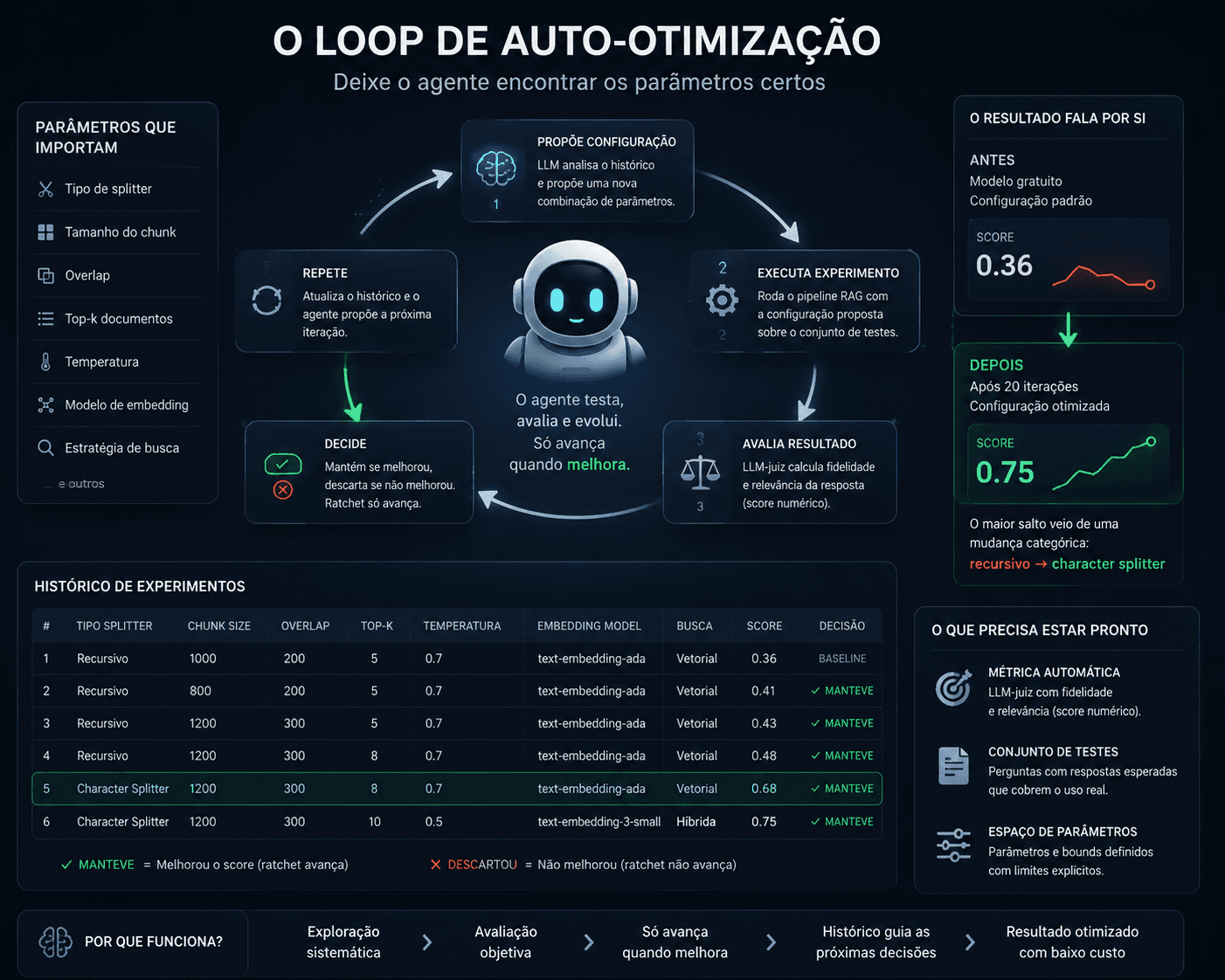
Deixar o agente encontrar os parâmetros certos: o loop de auto-otimização
Um pipeline RAG tem pelo menos meia dúzia de parâmetros que afetam a qualidade: tipo de chunking, tamanho, overlap, top-k, modelo de embedding, estratégia de busca. A maioria dos times testa esses parâmetros manualmente. Existe uma alternativa.