Modelo único para tudo ou pipeline de especialistas: o trade-off que ninguém resolve
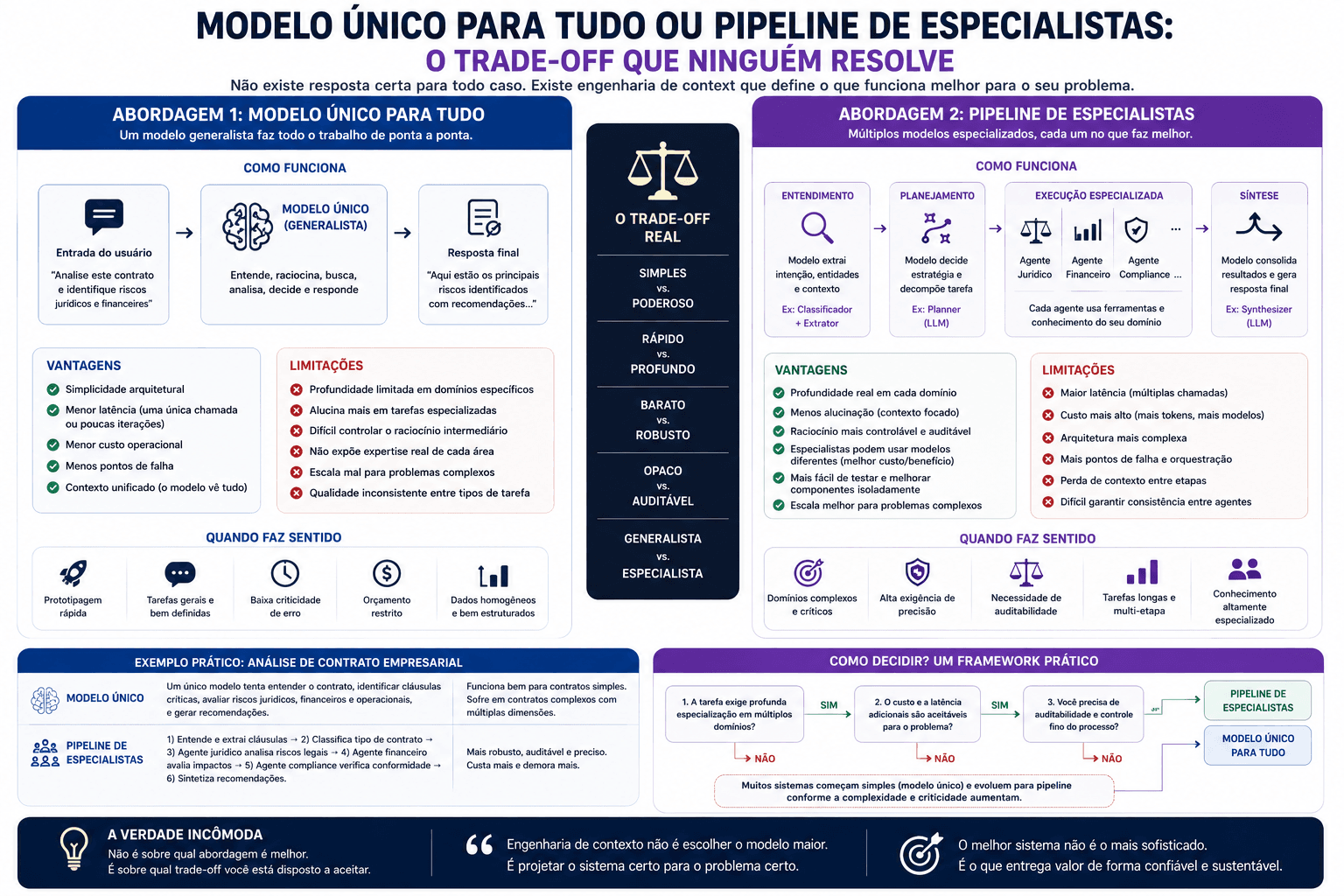
Modelo único para tudo ou pipeline de especialistas: o trade-off que ninguém resolve
Quando você precisa construir um agente que processa documentos com texto e imagens, transcreve áudio de reuniões, e analisa vídeos, você enfrenta uma decisão arquitetural com consequências reais: usar um modelo único que faz tudo, ou usar uma pipeline de modelos especializados.
O lançamento do Nemotron 3 Nano Omni pela Nvidia torna essa decisão mais concreta. O modelo combina, num único ponto de inferência, o backbone de texto do Nano (30B parâmetros com 3B ativos via MoE), um encoder de visão que suporta resolução arbitrária, e o encoder de áudio Parakeet que já alimentava os modelos de ASR deles. Texto, imagem, vídeo, e áudio entram e saem de um único modelo.
O argumento pelo modelo único
A vantagem óbvia é simplicidade operacional. Um modelo para fazer deploy, uma interface de API, um ponto de manutenção. Quando você está processando documentos que misturam texto e imagens, um modelo unificado pode raciocinar sobre a relação entre os dois modos sem que você precise coordenar esse contexto entre modelos separados.
Para agentes que precisam de inputs multimodais como parte de um fluxo mais amplo, isso simplifica o design da harness. Em vez de ter um componente para transcrição de áudio, outro para análise de imagem, e um terceiro para geração de texto, você passa o input composto para um único modelo e recebe o resultado.
O Nemotron Omni também traz algo que poucos modelos abertos têm: a receita de treinamento documentada em paper. Você sabe o que foi para dentro do modelo, como as diferentes modalidades foram integradas no treinamento, e quais dados foram usados. Isso importa quando você vai fazer fine-tuning ou quando precisa entender o comportamento do modelo em casos de borda.
O argumento pela pipeline especializada
O contra-argumento também tem peso. Modelos especializados tendem a ser mais precisos nas suas tarefas específicas. O Parakeet de ASR standalone tem performance de transcrição melhor do que o mesmo modelo integrado no Nemotron Omni, porque foi treinado exclusivamente para aquela tarefa.
Se você precisa transcrever audio de alta qualidade, um modelo de ASR dedicado é provavelmente a escolha certa. Se você precisa extrair texto de imagens com alta fidelidade em documentos complexos, um modelo de OCR especializado vai fazer melhor do que um modelo geral.
A pipeline especializada também permite substituir componentes individualmente. Quando um novo modelo de ASR melhor sai, você troca só aquele componente. Com um modelo unificado, a melhoria de uma modalidade exige atualizar o modelo inteiro.
O que os dados locais mudam na equação
O Nemotron Omni pode rodar localmente num servidor com GPU razoável usando vLLM. Isso é relevante para contextos empresariais onde os dados não podem sair da infraestrutura própria.
Documentos de RH com dados sensíveis de funcionários. Contratos com informação confidencial. Gravações de reuniões internas. Esses casos têm restrições de privacidade que podem tornar APIs de modelos externos inviáveis, independente da qualidade.
Para o tipo de automação que construo no Nexus ZDT, que processa dados de folha de pagamento e documentos de RH de múltiplas empresas, a capacidade de rodar multimodal localmente mudaria o que é possível oferecer sem comprometer privacidade dos dados dos clientes. A trade-off de qualidade versus controle de dados pode ser favorável a um modelo local um pouco menos preciso do que uma API externa mais precisa.
A decisão na prática
A decisão depende de três fatores: a importância relativa da qualidade em cada modalidade, as restrições de privacidade dos dados, e a tolerância para complexidade operacional.
Se qualidade de transcrição de áudio é crítica para o sistema, use um modelo de ASR dedicado. Se o sistema processa documentos mistos onde a relação entre texto e imagem importa para o raciocínio, um modelo unificado pode ser a melhor opção. Se os dados são sensíveis e precisam ficar locais, os modelos locais que funcionam com vLLM como o Nemotron Omni são um caminho que vale considerar.
O que mudou nos últimos meses é que a opção de modelos unificados locais de qualidade razoável passou a existir. A decisão hoje não é mais só entre qualidade máxima com API externa versus privacidade com modelo local fraco. Existe uma faixa média que antes não estava disponível.
Qual modalidade em sistemas que você opera hoje tem mais dados represados que nunca foram processados por IA por restrições de privacidade?
Assine a Newsletter
Receba conteúdo exclusivo sobre IA, LLMs e desenvolvimento em produção diretamente no seu email.
Sem spam. Cancele quando quiser.
Posts Relacionados
Seis padrões de arquitetura que todo agente vertical deveria implementar
O Claude Design virou referência não pelo que ele produz, mas por como ele foi construído. Seis padrões arquiteturais que aparecem nesse sistema podem ser extraídos e aplicados em qualquer agente vertical: jurídico, comercial, de RH, de operações.
O que é uma harness e por que a distinção com framework importa
Harness e framework não são sinônimos. Um framework te dá peças para montar um agente. Uma harness já é o agente, e você fornece o objetivo. Entender essa distinção muda o que você escolhe construir e por quê.

Informação presa em áudio e vídeo: o próximo conjunto de dados que agentes vão precisar acessar
A maioria dos sistemas RAG trabalha com documentos de texto. Mas nas organizações, uma parte significativa do conhecimento está em gravações de reuniões, apresentações em vídeo, e áudios de treinamento. RAG multimodal é o caminho para desbloquear esse contexto.