Informação presa em áudio e vídeo: o próximo conjunto de dados que agentes vão precisar acessar

Informação presa em áudio e vídeo: o próximo conjunto de dados que agentes vão precisar acessar
Quando você monta um sistema RAG corporativo, a primeira pergunta é: quais documentos você vai indexar? Manuais, contratos, políticas, relatórios, documentação técnica. Tudo isso tem uma coisa em comum: está em texto, ou pode ser convertido facilmente para texto.
O que fica de fora, quase sempre, é a informação que existe em forma de áudio e vídeo. Gravações de reuniões onde decisões foram tomadas. Apresentações de treinamento que nunca foram transcritas. Calls com clientes onde as objeções reais foram ditas. Vídeos de demonstração de produto que ensinam como usar um sistema melhor do que qualquer manual escrito.
Esses dados existem nas organizações. Só que não são consultáveis. Um agente que responde perguntas com base nos documentos da empresa não tem como acessar o que foi decidido na reunião de estratégia da semana passada, porque isso está num arquivo MP4.
Como RAG multimodal funciona
A pipeline básica de RAG multimodal para reuniões e vídeos tem três estágios de extração que acontecem antes de qualquer embedding:
O primeiro é ASR (Automatic Speech Recognition): o áudio é processado por um modelo de transcrição que converte a fala em texto. O resultado não é só texto bruto, é texto com timestamps e, dependendo do modelo, com identificação de locutor. Isso permite rastrear quem disse o quê e quando.
O segundo é processamento visual dos frames de vídeo: modelos de visão-linguagem geram descrições textuais do que está acontecendo nas cenas. Para uma reunião gravada com apresentação de slides, isso captura o conteúdo visual dos slides que não aparece no áudio. Para vídeos de demonstração, captura ações na interface que estão sendo realizadas mas não necessariamente verbalizadas.
O terceiro é embedding e indexação: o texto extraído de áudio e vídeo vai para o mesmo pipeline de embedding e indexação que os documentos de texto. Para o sistema de recuperação, não importa se o chunk veio de um PDF ou de um vídeo; o que importa é a similaridade semântica com a query.
O que muda no raciocínio disponível para o agente
A diferença prática é que o agente passa a ter acesso a contexto temporal e conversacional que documentos de texto não capturam.
Um documento de política da empresa diz o que é a política. Uma gravação de reunião diz por que a política foi decidida dessa forma, quais alternativas foram consideradas e descartadas, e quais eram as preocupações que o time tinha na época. Esses são tipos de conhecimento fundamentalmente diferentes, e o segundo não existe em nenhum texto escrito na maioria das organizações.
Para sistemas de onboarding, a diferença é ainda mais concreta. Os melhores materiais de treinamento de um vendedor experiente não estão nos PDFs de treinamento, estão nas ligações gravadas onde ele conduziu objeções de clientes em situações reais. Indexar essas ligações transforma o que o agente pode oferecer como contexto.
Onde as complexidades aparecem
O pipeline tem desafios que não existem no RAG de texto puro.
Tamanho dos arquivos: um vídeo de 60 minutos pode ter vários gigabytes de dados antes de processamento. A extração de ASR e frames precisa acontecer de forma eficiente e, idealmente, em paralelo.
Qualidade do áudio: ruído de fundo, múltiplas pessoas falando ao mesmo tempo, sotaques, termos técnicos de domínio específico. Modelos de ASR gerais cometem mais erros em contextos de reunião real do que em áudio limpo. O erro de transcrição se propaga para a qualidade do que é indexado.
Atribuição de fonte: quando o agente recupera um chunk de uma gravação, o usuário precisa conseguir entender de onde aquela informação veio. "Na reunião de estratégia do dia 15, João disse que..." é muito mais útil do que "num áudio recuperado". Isso exige metadados estruturados na indexação.
Para organizações que já estão construindo sistemas RAG para documentos de texto, adicionar a camada multimodal é o próximo passo natural. O conhecimento que está represado em áudio e vídeo é, em muitos casos, o conhecimento mais valioso e menos acessível da organização.
Que tipo de informação na sua organização existe só em gravações e nunca é consultável por quem mais precisaria delas?
Assine a Newsletter
Receba conteúdo exclusivo sobre IA, LLMs e desenvolvimento em produção diretamente no seu email.
Sem spam. Cancele quando quiser.
Posts Relacionados
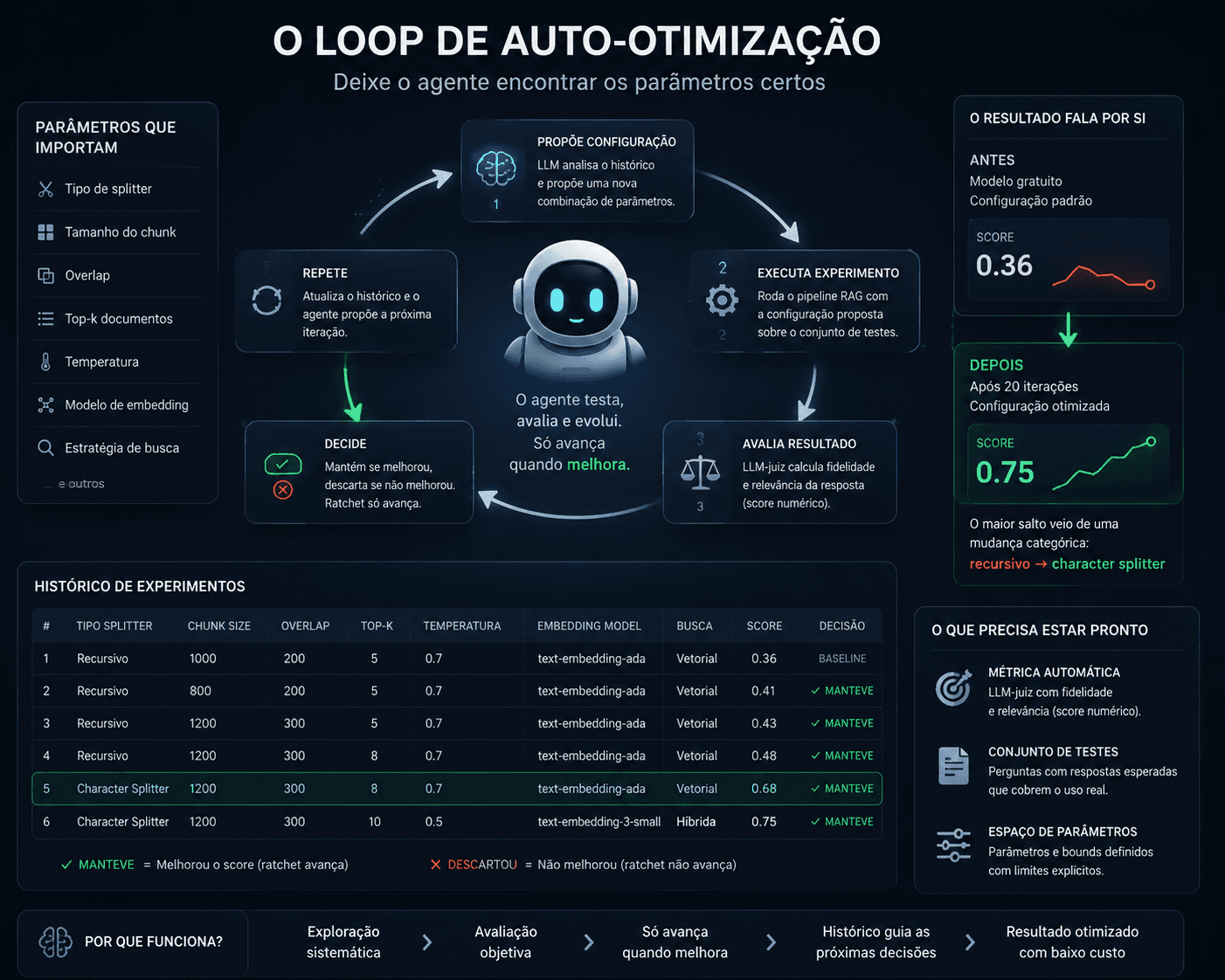
Deixar o agente encontrar os parâmetros certos: o loop de auto-otimização
Um pipeline RAG tem pelo menos meia dúzia de parâmetros que afetam a qualidade: tipo de chunking, tamanho, overlap, top-k, modelo de embedding, estratégia de busca. A maioria dos times testa esses parâmetros manualmente. Existe uma alternativa.
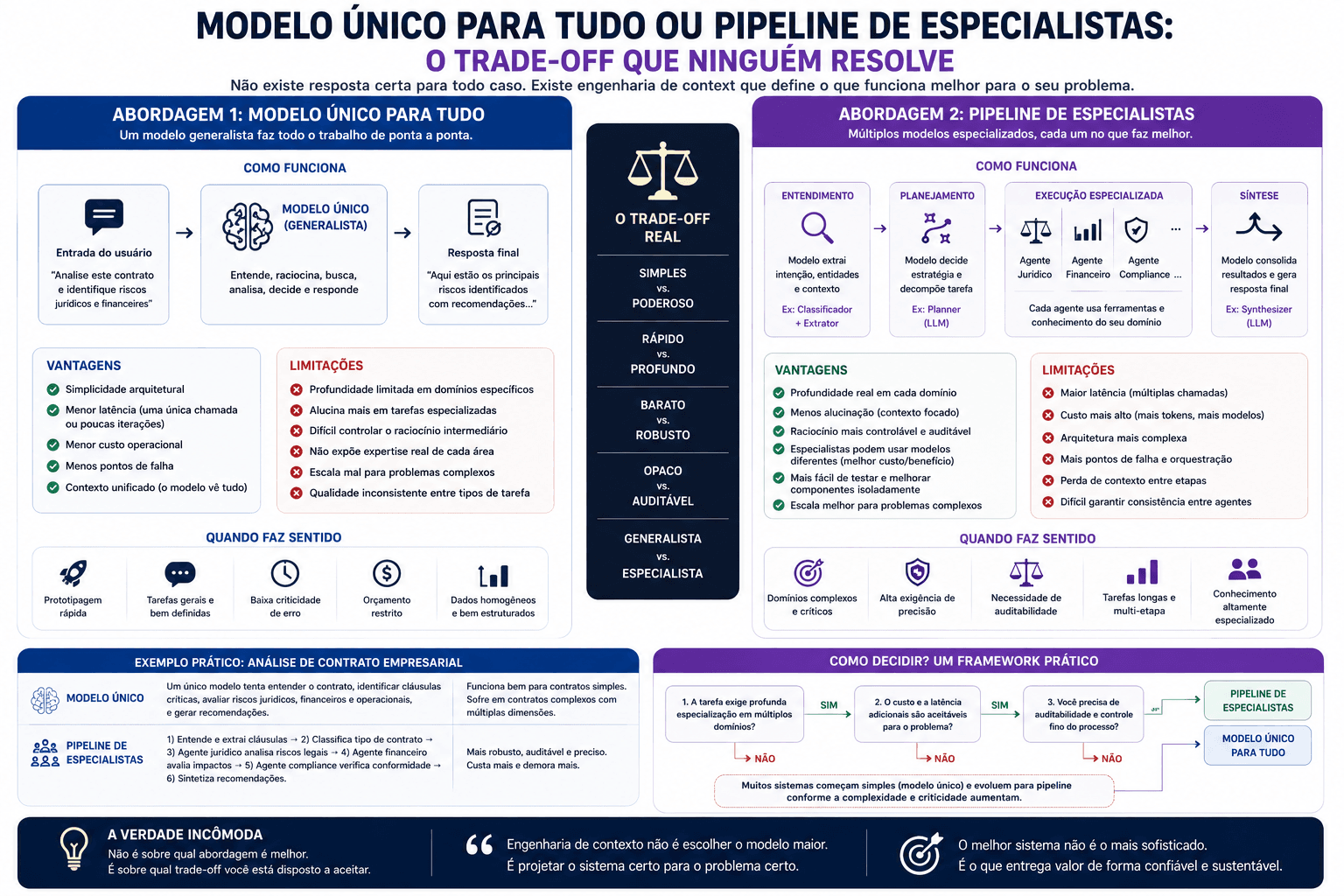
Modelo único para tudo ou pipeline de especialistas: o trade-off que ninguém resolve
A Nvidia lançou o Nemotron 3 Nano Omni: um modelo que processa texto, imagem, vídeo e áudio ao mesmo tempo, com receitas de treinamento abertas e documentadas. Isso levanta uma decisão arquitetural real para quem constrói agentes multimodais.
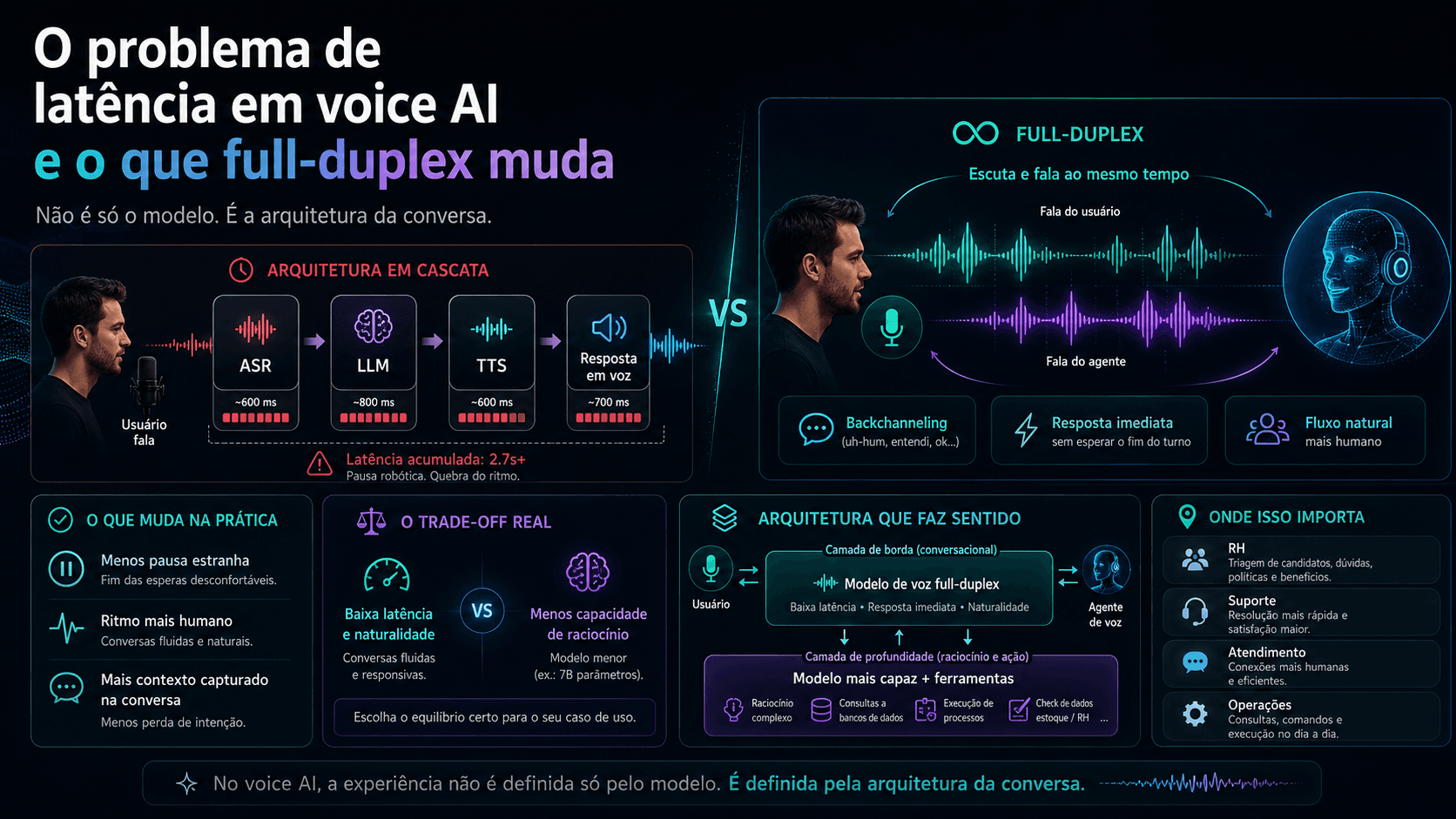
O problema de latência em voice AI e o que full-duplex muda
Todo sistema de voz que você já usou tem o mesmo problema: três modelos em cadeia gerando três atrasos que se acumulam. O PersonaPlex resolveu isso com uma arquitetura diferente. Mas resolveu uma coisa e introduziu outra.