O problema de latência em voice AI e o que full-duplex muda
O problema de latência em voice AI e o que full-duplex muda
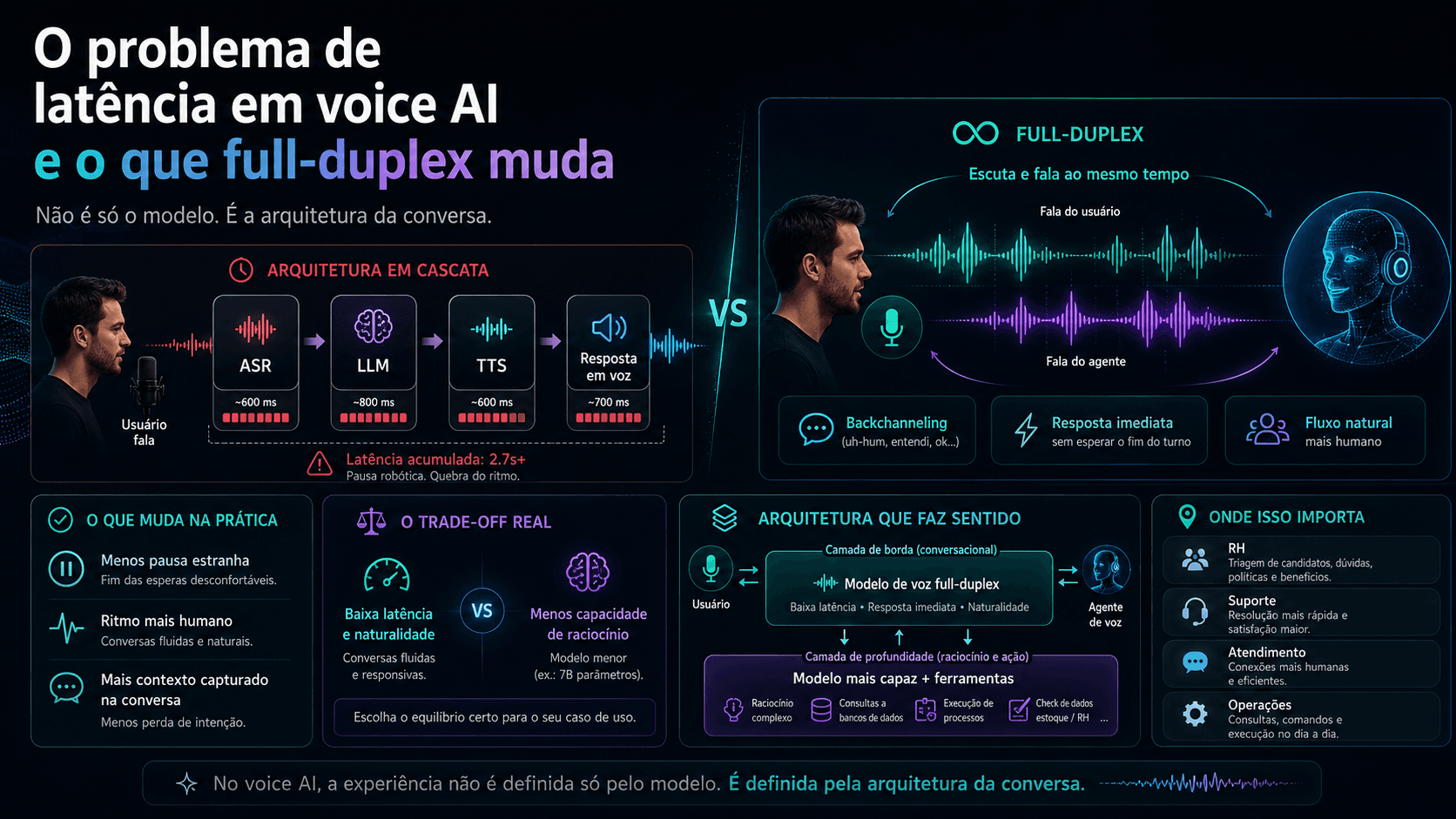
Existe um padrão na maioria dos sistemas de voz com IA que explica por que a experiência ainda parece robótica. Não é o modelo. É a arquitetura em cascata.
O fluxo padrão é: você fala, o ASR transcreve o áudio em texto, o texto vai para o LLM, o LLM gera a resposta em texto, o TTS converte o texto em fala, você escuta. Cada um desses três estágios adiciona latência. O modelo de transcrição tem sua própria latência. O LLM tem sua própria latência. O modelo de síntese de voz tem a sua. As três se acumulam.
O resultado é o que você reconhece como a pausa estranha antes de qualquer resposta, que faz a conversa parecer mecânica independente de quão boa seja a qualidade da voz.
A abordagem full-duplex
O PersonaPlex da Nvidia, um modelo de 7B parâmetros baseado na arquitetura Moshi, opera de forma diferente: escuta e fala acontecem de forma concorrente, em streams simultâneos. Não existe turno de processamento. O modelo está processando o áudio enquanto você ainda está falando e pode começar a responder sem esperar o fim da sua frase.
O resultado prático é que a conversa tem ritmo humano. O agente interrompe. Dá backchanneling com "uh-huh" no meio das suas frases. Responde imediatamente quando você termina. Não porque foi programado para isso com truques de timing, mas porque está processando áudio em tempo real da mesma forma que processaria texto.
Além disso, o PersonaPlex mantém a capacidade de customizar papel e voz. Um dos problemas de modelos full-duplex anteriores (como o Moshi) era que a voz e o papel eram fixos no modelo. O PersonaPlex resolve isso: você define um system prompt de papel (assistente de restaurante, DevOps engineer, recepcionista médica) e escolhe entre uma biblioteca de vozes. A persona é injetada sem precisar retreinar o modelo.
O trade-off que não desaparece
Há um limite real nessa arquitetura que importa para quem está pensando em aplicar isso em sistemas de produção: o modelo tem 7 bilhões de parâmetros.
Em comparação com modelos como Claude ou GPT, que operam na faixa de centenas de bilhões de parâmetros ativos, um 7B tem raciocínio significativamente mais limitado. Para conversas simples com papel bem definido, como atendimento de restaurante ou suporte técnico básico, funciona bem. Para raciocínio complexo, interpretação de casos de borda, ou situações que exigem múltiplas peças de conhecimento simultâneas, começa a falhar de formas que um modelo maior não falharia.
A questão aberta é como conectar esse modelo a ferramentas externas para compensar as limitações do modelo base. Um agente de voz full-duplex que pode fazer chamadas de ferramenta durante a conversa (consultar banco de dados, verificar estoque, acionar processos) seria a combinação que faz sentido para casos de uso empresariais sérios. A tecnologia para fazer isso ainda está sendo desenvolvida.
Onde isso muda o cálculo para agentes empresariais
Quando penso em casos como o Nexus ZDT, onde o agente precisa responder perguntas de funcionários sobre folha de pagamento e processos de RH, a interface de voz com latência natural é relevante. A maioria dos usuários prefere falar do que digitar, especialmente para consultas rápidas no meio de uma tarefa.
A arquitetura atual do Nexus ZDT usa texto como interface principal. Adicionar voz na borda exigiria exatamente esse tipo de modelo: algo que responde imediatamente, que soa natural, mas que está conectado ao modelo mais capaz que faz o raciocínio real. O modelo de voz seria a borda de ingestão, não o processador central.
O que muda com full-duplex não é só a experiência do usuário. É a arquitetura de como você captura contexto. Um usuário que está falando naturalmente com um agente vai dar muito mais contexto do que um usuário que está digitando em caixas de texto. O challenge é extrair estrutura do que é essencialmente stream de áudio.
Em que tipo de processo empresarial uma interface de voz com resposta imediata mudaria o comportamento dos usuários de forma significativa?
Assine a Newsletter
Receba conteúdo exclusivo sobre IA, LLMs e desenvolvimento em produção diretamente no seu email.
Sem spam. Cancele quando quiser.
Posts Relacionados

Informação presa em áudio e vídeo: o próximo conjunto de dados que agentes vão precisar acessar
A maioria dos sistemas RAG trabalha com documentos de texto. Mas nas organizações, uma parte significativa do conhecimento está em gravações de reuniões, apresentações em vídeo, e áudios de treinamento. RAG multimodal é o caminho para desbloquear esse contexto.
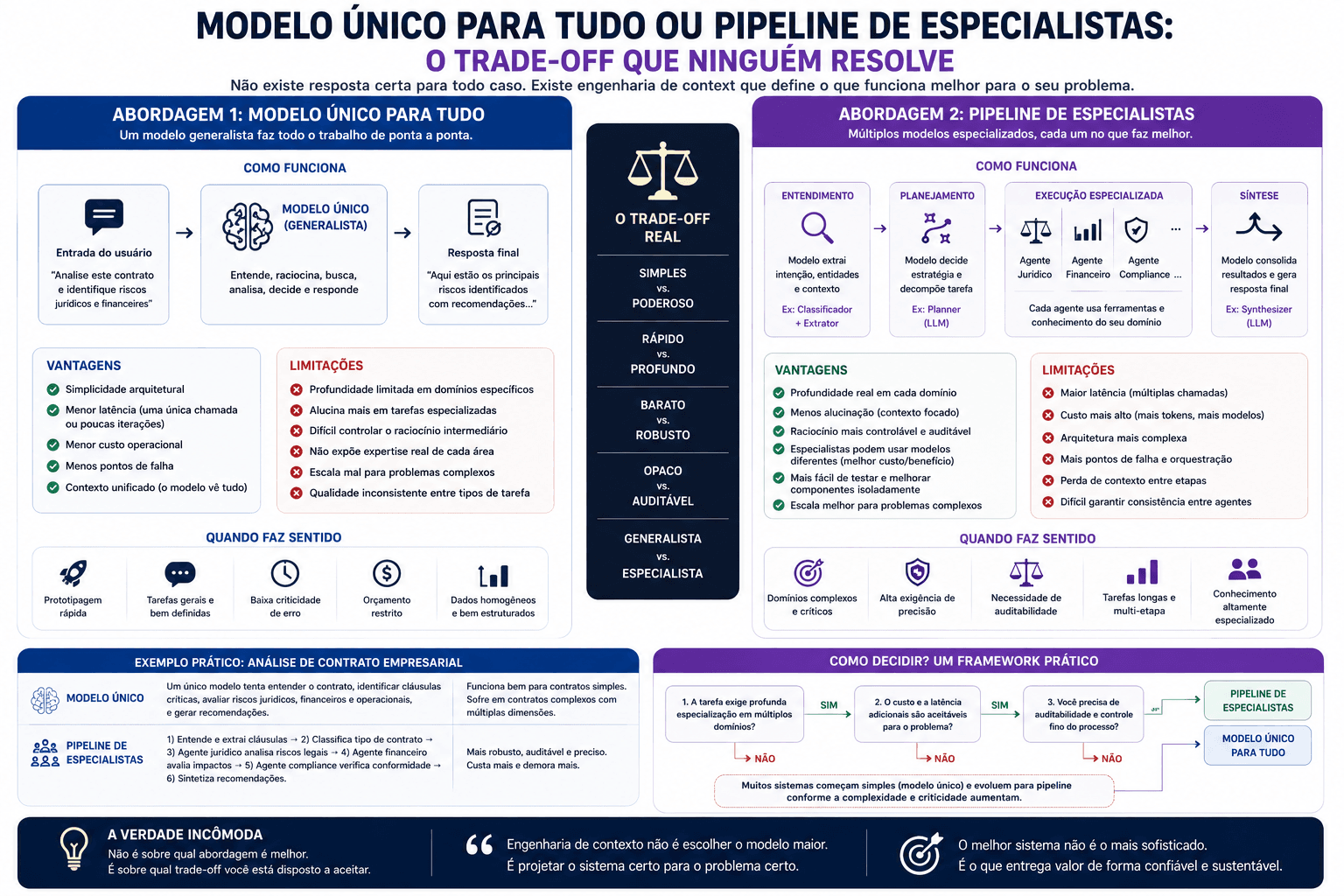
Modelo único para tudo ou pipeline de especialistas: o trade-off que ninguém resolve
A Nvidia lançou o Nemotron 3 Nano Omni: um modelo que processa texto, imagem, vídeo e áudio ao mesmo tempo, com receitas de treinamento abertas e documentadas. Isso levanta uma decisão arquitetural real para quem constrói agentes multimodais.
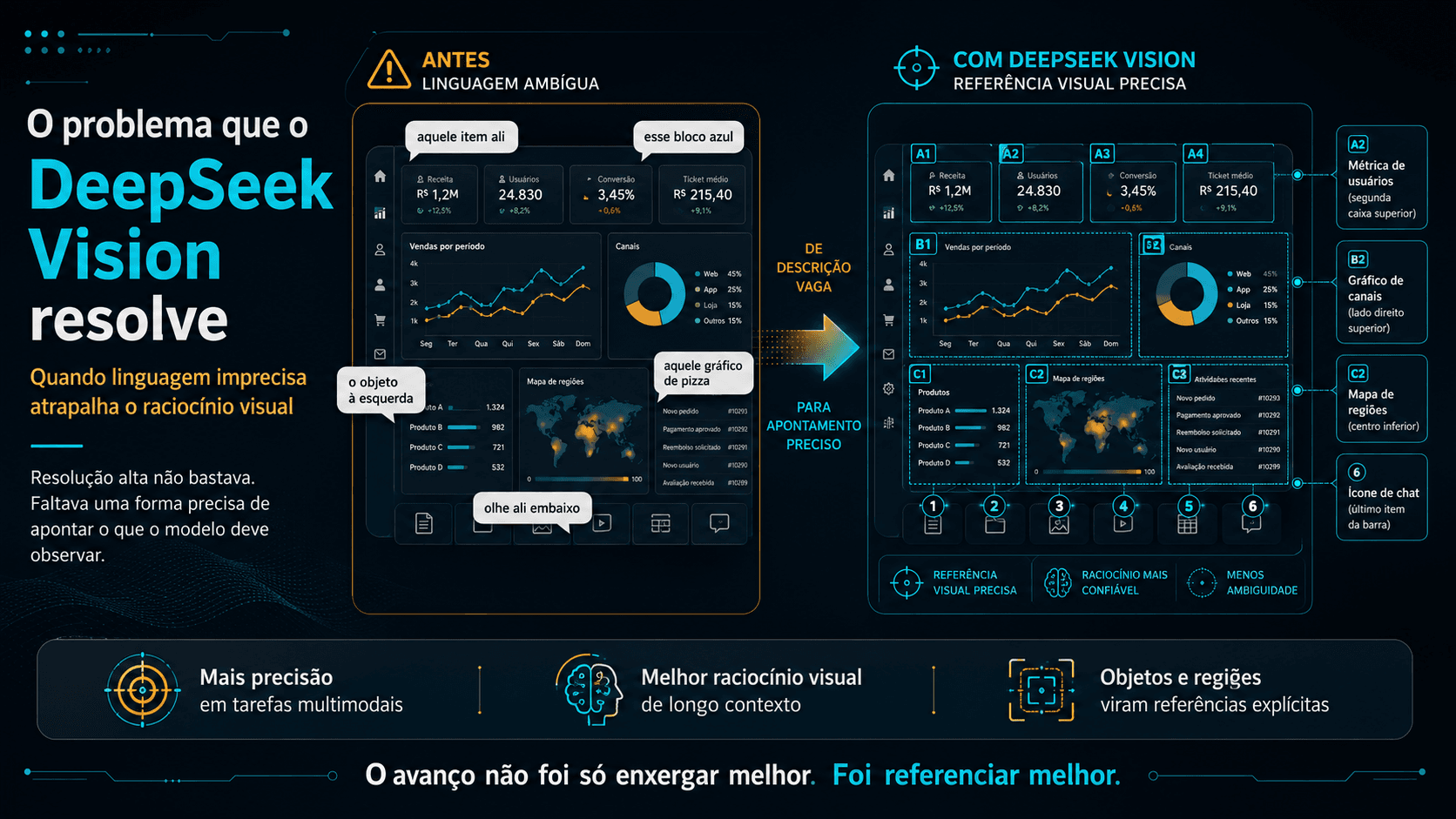
O problema que o DeepSeek Vision resolve que ninguém estava falando
Modelos multimodais evoluíram muito em resolução e detalhamento. Mas havia um gap diferente e mais fundamental: a linguagem é imprecisa para apontar objetos num raciocínio visual longo. O DeepSeek Vision resolveu isso de uma forma inesperadamente elegante.