O problema que o DeepSeek Vision resolve que ninguém estava falando
O problema que o DeepSeek Vision resolve que ninguém estava falando
Em 2024, a evolução dos modelos multimodais ficou concentrada em um problema: como fazer o modelo ver melhor. Alta resolução, cropping dinâmico, processamento de patches em múltiplas escalas. Isso foi importante, e quase todos os grandes labs trabalharam nisso.
O paper mais recente do time de visão do DeepSeek argumenta que existe um segundo gap, diferente e mais fundamental, que o mercado não estava atacando. Eles chamam de reference gap.
O problema da imprecisão da linguagem
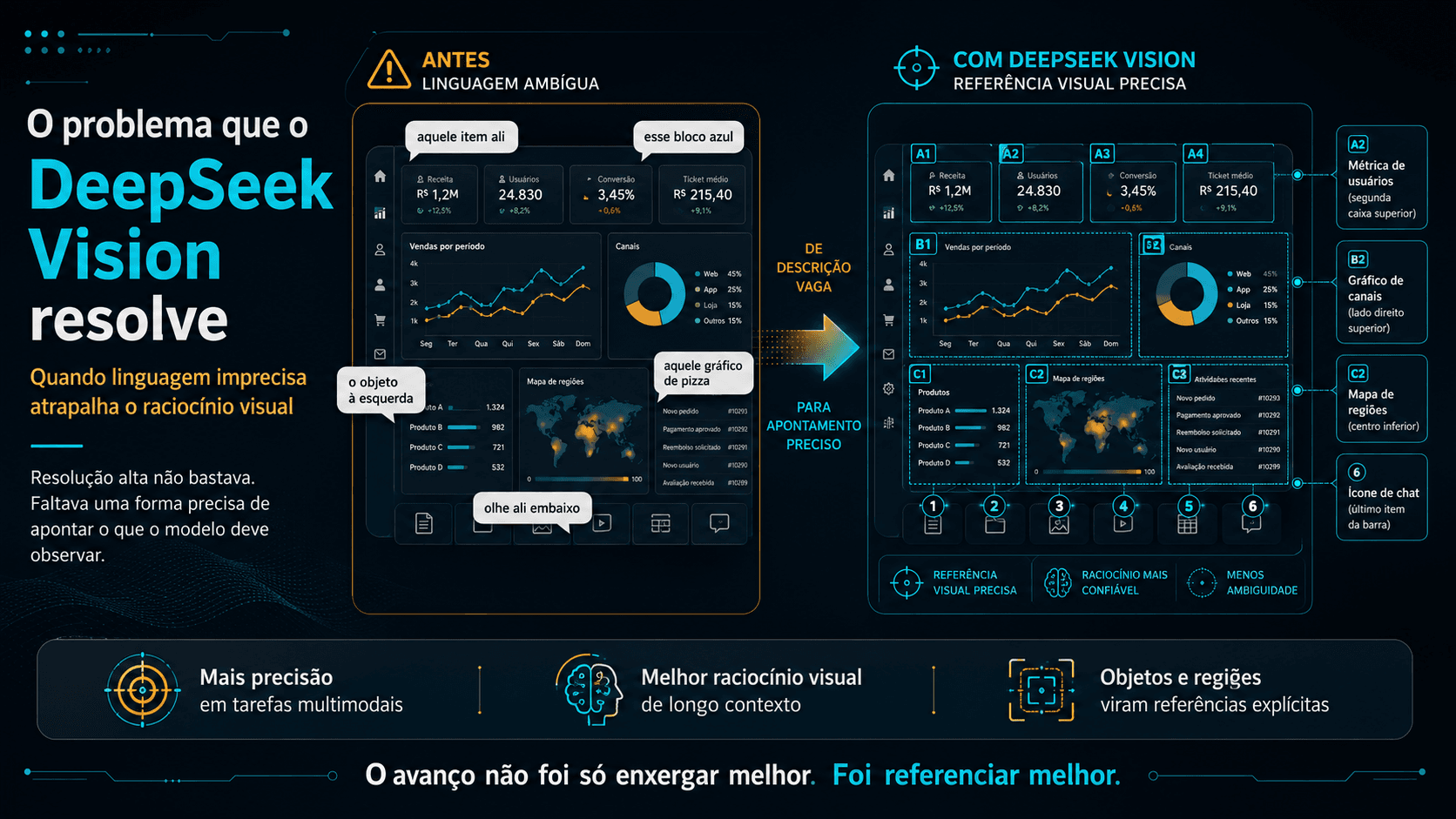
Quando você pede para um modelo contar pessoas numa foto de time com muita gente, o modelo pode ver todos. Mas à medida que o raciocínio se estende, a linguagem fica imprecisa para rastrear cada entidade individualmente. "O homem de camisa azul à esquerda da mulher com chapéu" começa a ambiguidade acumular. O modelo perde o fio de qual entidade está raciocioando quando a cadeia fica longa.
Humanos resolvem isso com gestos, com o dedo apontando. Modelos, até agora, não tinham o equivalente.
A solução: tokens de coordenada no chain of thought
O que o DeepSeek Vision introduz são tokens especiais de bounding box e ponto como parte nativa do vocabulário do modelo. Não é function calling. Não é uma ferramenta externa. São tokens que o modelo emite inline no raciocínio, da mesma forma que emite texto.
Quando o modelo está contando pessoas numa imagem densa, ele escreve o raciocínio e inclui, para cada pessoa identificada, as coordenadas da bounding box como parte do pensamento. Isso cria uma referência explícita e persistente ao longo de toda a cadeia de raciocínio. O modelo literalmente aponta para o que está analisando.
A consequência prática aparece exatamente nos problemas onde a linguagem é estruturalmente ruim: navegação de labirinto, rastreamento de caminhos, contagem em cenas densas, raciocínio topológico. Nos benchmarks específicos para esses tipos de tarefa, a diferença é expressiva. Em navegação de labirinto, por exemplo, 17 pontos acima do GPT. Não porque o modelo vê melhor. Porque ele consegue manter rastreamento preciso durante o raciocínio.
A história de eficiência que é mais impressionante que parece
Além da parte arquitetural, o paper tem uma história de eficiência que merece atenção separada.
Para uma imagem de 80x80 pixels, o DeepSeek Vision usa cerca de 81 entradas no KV cache. Claude Sonnet usa cerca de 870. Gemini 3 Flash usa cerca de 1100. Isso é quase 10x menos.
O caminho para chegar nisso é uma pipeline de compressão em múltiplas etapas: a imagem vira patches, patches vizinhos são comprimidos juntos por convolução esparsa, e o mecanismo de atenção comprimida do V4 reduz o KV cache por mais um fator de 4. A partir de uma imagem que começa com milhões de pixels, você chega a 81 tokens no KV cache.
Isso importa economicamente de uma forma muito direta: processar imagens com esse modelo custa uma fração do que custa com os equivalentes. Para sistemas empresariais que processam documentos em volume, a diferença entre 870 e 81 tokens de contexto por imagem é a diferença entre escalar ou não.
O que isso significa para quem constrói com multimodal
Quando construo pipelines que precisam processar documentos do ERP, o problema não é só extrair texto. É extrair estrutura, identificar campos específicos em formulários, entender relações entre elementos visuais que têm posição relevante na página.
A capacidade de um modelo raciocinar com coordenadas explícitas muda a qualidade do que você consegue extrair de documentos complexos. Em vez de "o valor que parece estar no campo de data", o modelo pode apontar exatamente onde na imagem está o dado que está analisando. Isso é auditável, rastreável, e muda o nível de confiança que você pode ter no resultado.
O time do DeepSeek foi honesto sobre as limitações: o modo de primitivas visuais precisa ser ativado explicitamente, o modelo é sensível à resolução, e o raciocínio topológico ainda não generaliza bem para todos os cenários. Mas a direção é clara.
O que me parece mais relevante para sistemas em produção é a combinação de raciocínio grounded com custo operacional significativamente menor. Essas duas coisas juntas mudam o cálculo de viabilidade para processamento visual em escala.
Que tipo de documento ou imagem no seu domínio se beneficiaria de um modelo que pode apontar com precisão para o que está analisando, em vez de descrever em linguagem natural?
Assine a Newsletter
Receba conteúdo exclusivo sobre IA, LLMs e desenvolvimento em produção diretamente no seu email.
Sem spam. Cancele quando quiser.
Posts Relacionados

Informação presa em áudio e vídeo: o próximo conjunto de dados que agentes vão precisar acessar
A maioria dos sistemas RAG trabalha com documentos de texto. Mas nas organizações, uma parte significativa do conhecimento está em gravações de reuniões, apresentações em vídeo, e áudios de treinamento. RAG multimodal é o caminho para desbloquear esse contexto.
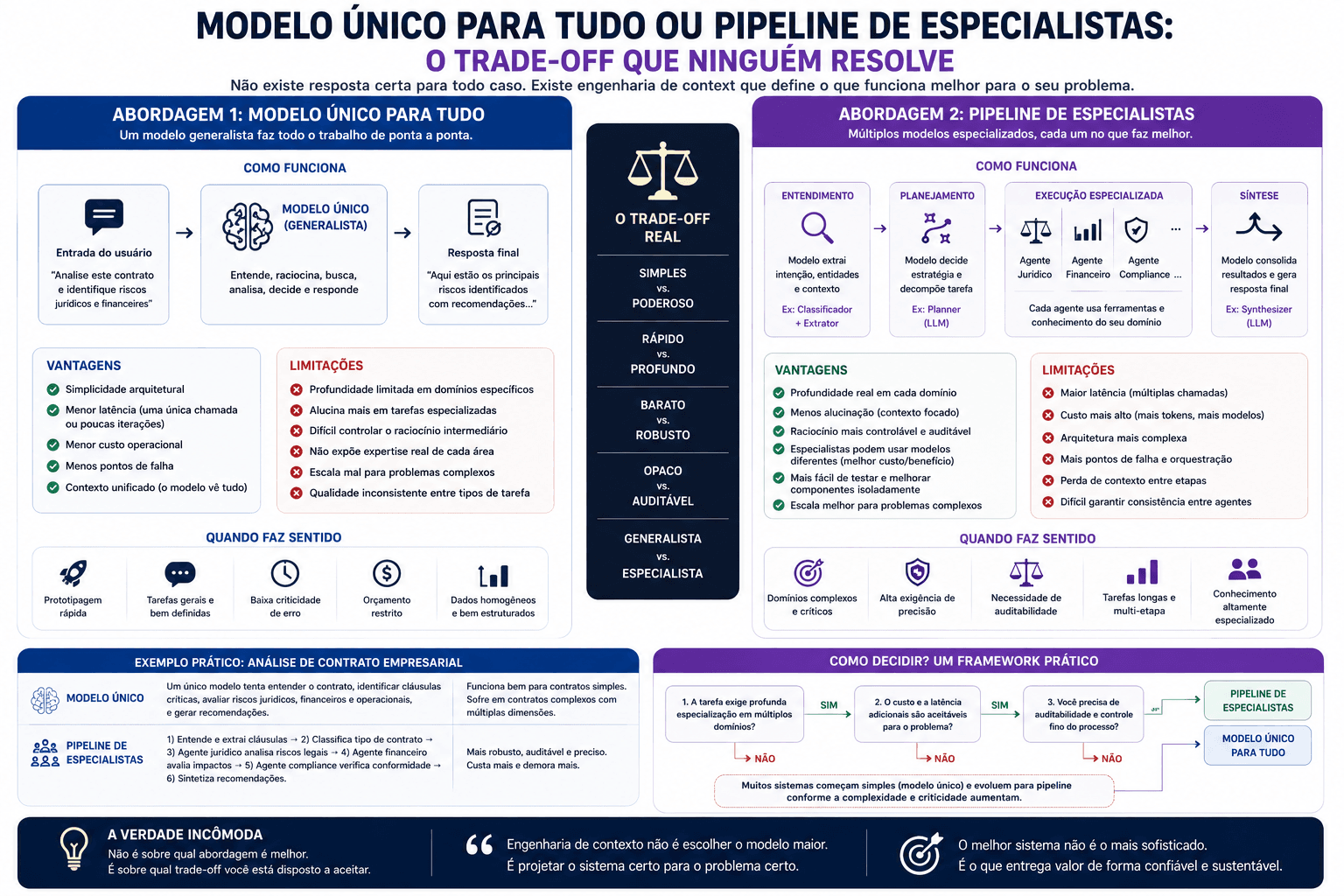
Modelo único para tudo ou pipeline de especialistas: o trade-off que ninguém resolve
A Nvidia lançou o Nemotron 3 Nano Omni: um modelo que processa texto, imagem, vídeo e áudio ao mesmo tempo, com receitas de treinamento abertas e documentadas. Isso levanta uma decisão arquitetural real para quem constrói agentes multimodais.
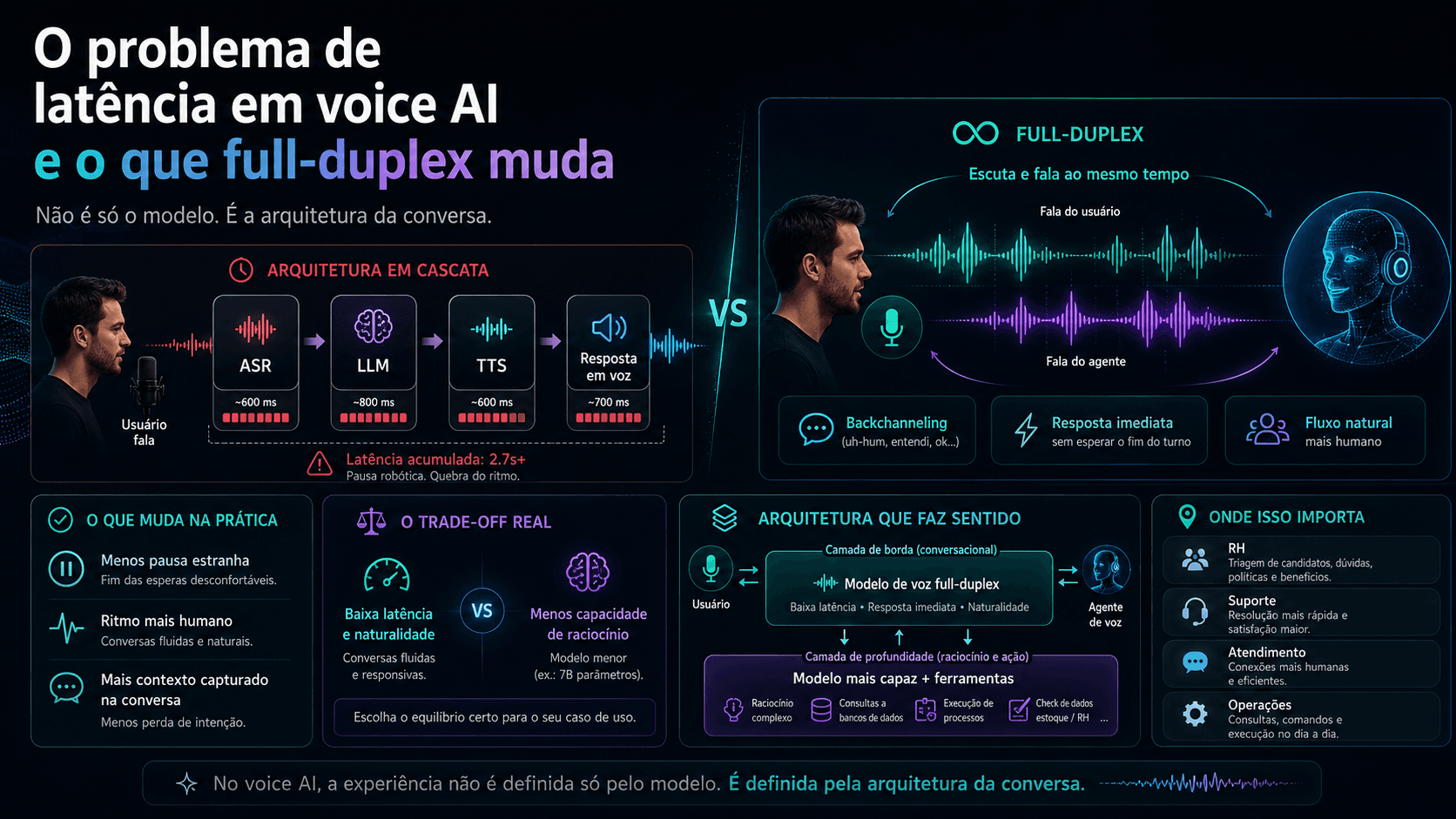
O problema de latência em voice AI e o que full-duplex muda
Todo sistema de voz que você já usou tem o mesmo problema: três modelos em cadeia gerando três atrasos que se acumulam. O PersonaPlex resolveu isso com uma arquitetura diferente. Mas resolveu uma coisa e introduziu outra.