Multi-tenancy em agentes: onde a separação de dados tem que ser feita
Multi-tenancy em agentes: onde a separação de dados tem que ser feita
Quando você deploya um agente em produção que vai atender múltiplos usuários ou múltiplas empresas, o primeiro problema que aparece não é o modelo. É a separação de contexto.
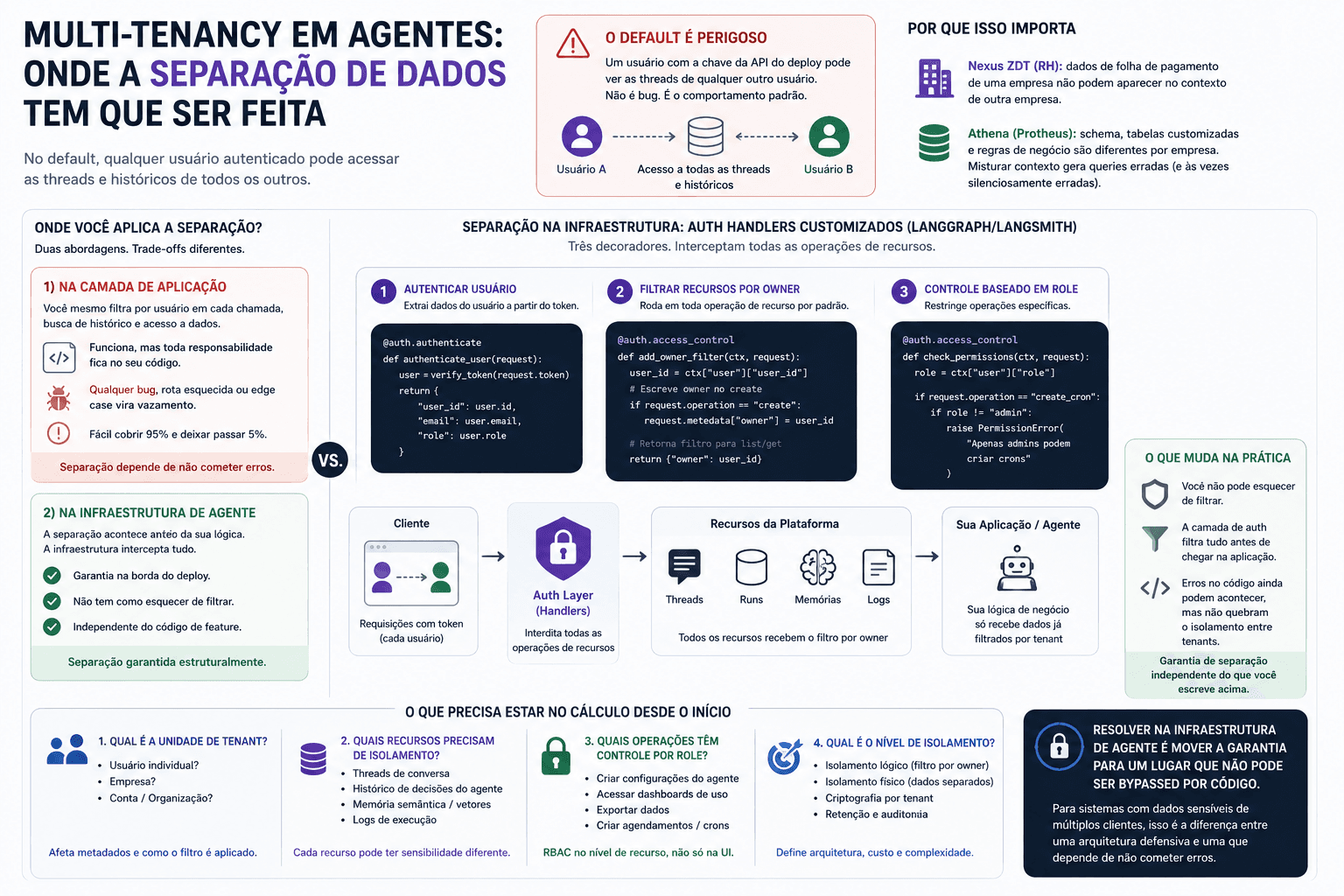
O default de deploys de agente é perigoso de uma forma silenciosa: os dados existem, as threads existem, os históricos de conversa existem. Eles ficam acessíveis para qualquer usuário que fizer uma chamada autenticada com a chave da API do deploy. Um usuário pode ver as threads de outro usuário. Isso não é um bug de implementação. É o comportamento padrão.
Por que isso aparece em sistemas reais
No Nexus ZDT, a plataforma de automação de RH que atende múltiplas empresas no Protheus, a separação de contexto é não-negociável. Os dados de folha de pagamento da empresa A não podem aparecer num contexto que processa uma requisição da empresa B. Quando o pipeline tem contexto de múltiplas fontes, você precisa de garantias estruturais de que o vazamento não é possível, não de esperança de que o modelo vai distinguir corretamente.
O mesmo vale para o Athena. Cada empresa tem seu próprio schema no Protheus, suas próprias tabelas customizadas, suas próprias regras de negócio. Um agente que confunde o contexto de duas empresas gera queries erradas, às vezes silenciosamente erradas.
A pergunta que importa é: onde você aplica a separação?
As opções e seus trade-offs
A primeira opção é aplicar na camada de aplicação: você mesmo controla qual contexto passa para o modelo em cada chamada, você filtra por usuário antes de buscar histórico, você não expõe rotas que cruzam dados de tenants. Isso funciona, mas coloca toda a responsabilidade na sua lógica de aplicação. Qualquer bug, qualquer rota que você esqueceu de filtrar, qualquer edge case no código de busca, vira um vazamento.
A segunda opção é aplicar na infraestrutura de agente, antes das chamadas chegarem na sua lógica. É o que o LangGraph/LangSmith permite com auth handlers customizados: você define a lógica de autenticação e controle de acesso numa camada que intercepta todas as operações de recursos.
O mecanismo é simples: três decoradores. O primeiro autentica o usuário a partir do token e retorna um dicionário com os dados do usuário (ID, email, role). O segundo, que roda em toda operação de recurso por padrão, escreve o ID do usuário como owner nos metadados do recurso e retorna esse filtro automaticamente. O resultado: quando um usuário lista suas threads, a infraestrutura devolve apenas as threads que ele criou, sem nenhuma lógica adicional na aplicação. O terceiro permite controle baseado em role para operações específicas, como restringir criação de crons para admins.
Não tem middleware customizado. Não tem query de banco por request. A separação acontece na borda do deploy.
O que muda quando a separação está na infraestrutura
A diferença prática é que você não pode esquecer de filtrar. Se a separação está na aplicação, qualquer código novo que você escreve tem que se lembrar de aplicar o filtro. Rotas de API, ferramentas do agente, buscas de histórico, qualquer acesso a dado. É fácil cobrir 95% e deixar um endpoint de edge case sem o filtro.
Se a separação está na infraestrutura de agente, você não tem como deixar passar. A camada de auth intercepta tudo antes de chegar na sua lógica. Você ainda pode cometer erros na aplicação, mas a separação base entre tenants está garantida independente do que você escreva acima.
O que precisa estar no cálculo desde o início
Quando você projeta um agente que vai atender múltiplos tenants, as decisões de separação de contexto precisam estar no design, não no retrofitting. As perguntas que precisam ter resposta antes do código:
Qual é a unidade de tenant? Usuário individual? Empresa? Conta? A resposta afeta como você estrutura os metadados de recursos e como o filtro é aplicado.
Quais recursos precisam de isolamento? Threads de conversa, histórico de decisões do agente, memória semântica, logs de execução? Cada um pode ter um nível diferente de sensibilidade.
Quais operações têm controle por role? Criar configurações do agente, acessar dashboards de uso, exportar dados? Role-based access control no nível de recurso é diferente de RBAC no nível de feature da UI.
Resolver isso na infraestrutura de agente em vez de na aplicação move a garantia de separação para um lugar que não pode ser bypassado por código de feature. Para sistemas em produção com dados sensíveis de múltiplos clientes, isso é a diferença entre uma arquitetura defensiva e uma que depende de não cometer erros.
Em qual camada você está aplicando multi-tenancy nos sistemas de agente que você opera?
Assine a Newsletter
Receba conteúdo exclusivo sobre IA, LLMs e desenvolvimento em produção diretamente no seu email.
Sem spam. Cancele quando quiser.
Posts Relacionados
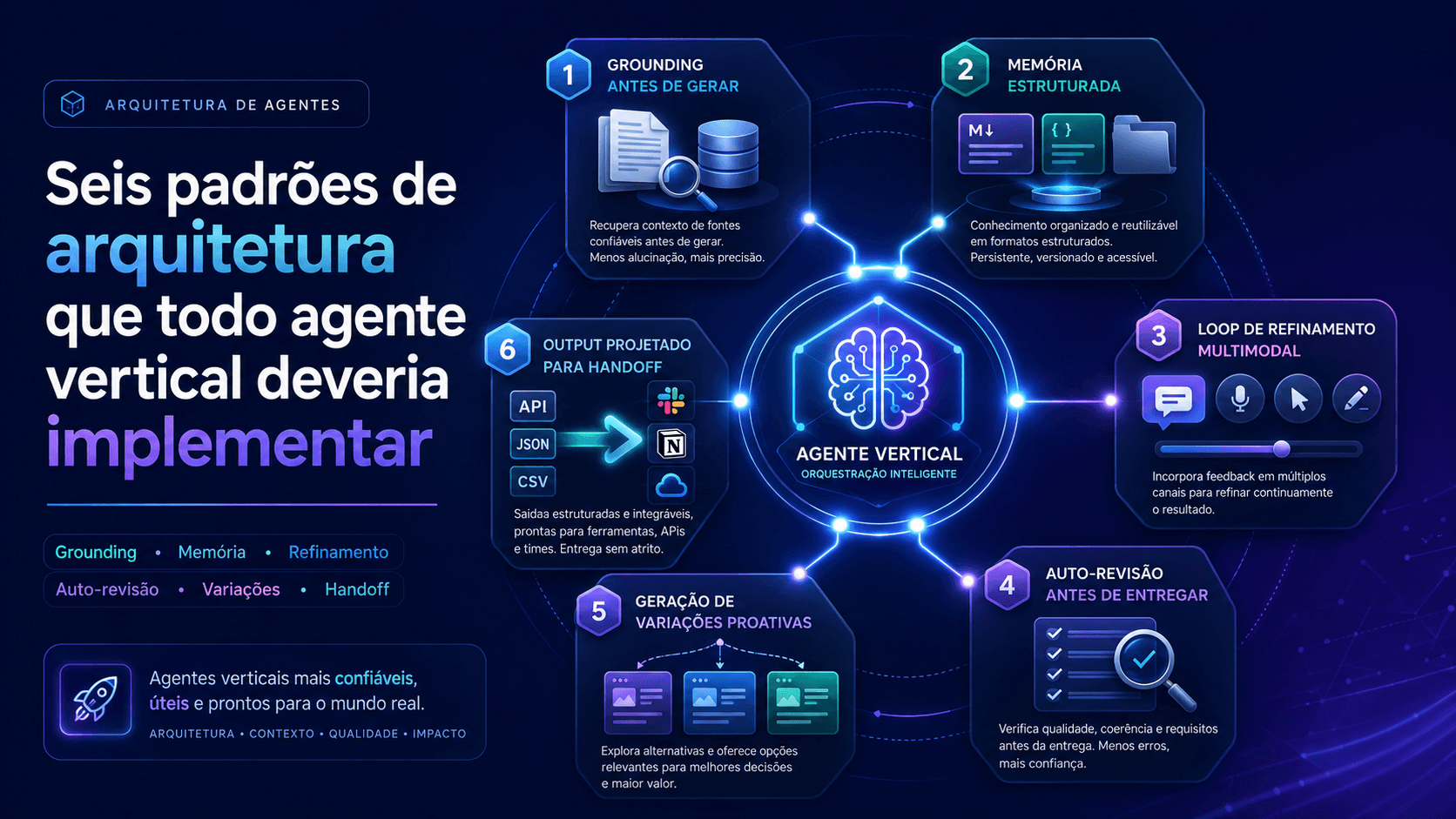
Seis padrões de arquitetura que todo agente vertical deveria implementar
O Claude Design virou referência não pelo que ele produz, mas por como ele foi construído. Seis padrões arquiteturais que aparecem nesse sistema podem ser extraídos e aplicados em qualquer agente vertical: jurídico, comercial, de RH, de operações.
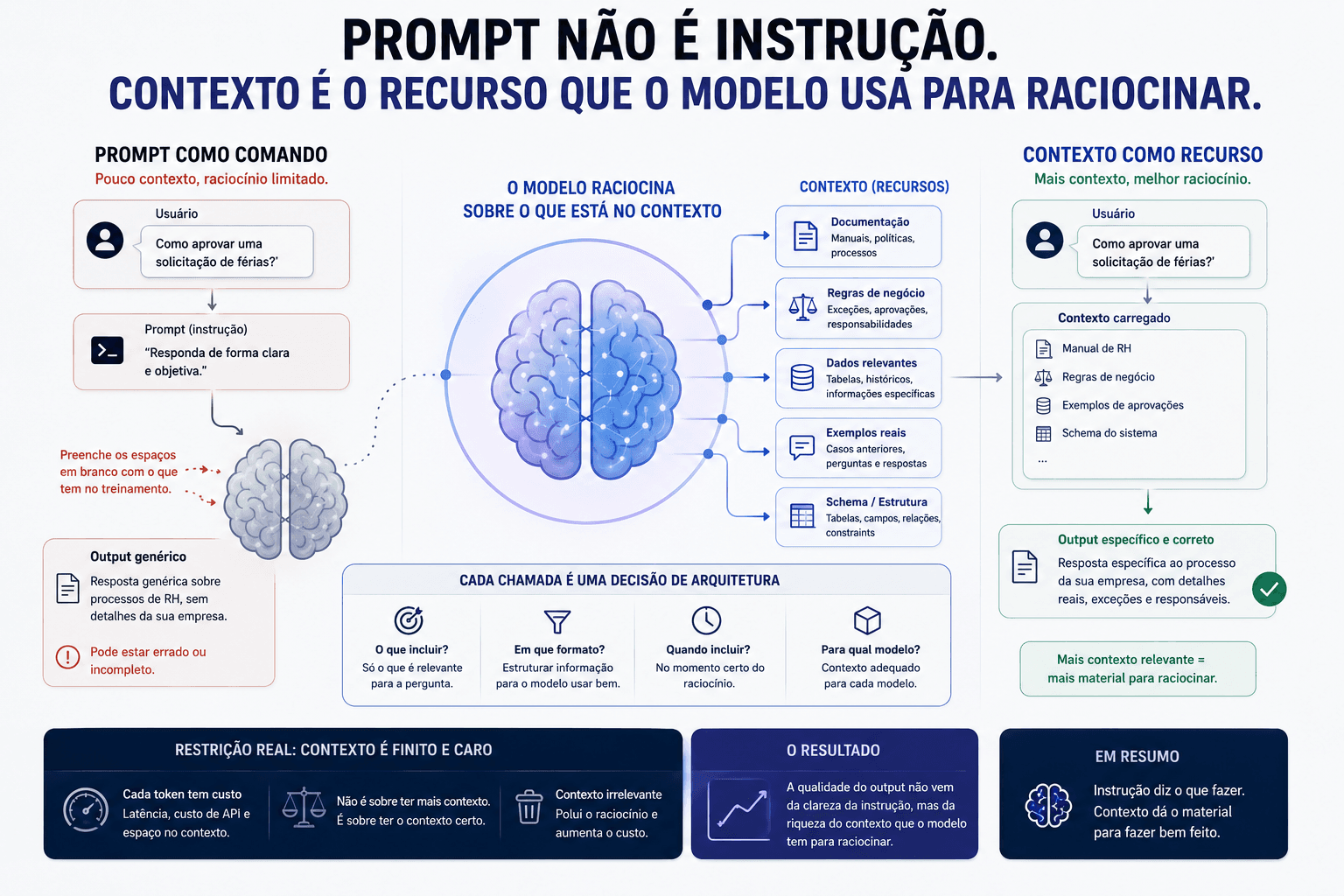
Prompt não é instrução. Contexto é o recurso que o modelo usa para raciocinar
A maioria das pessoas ainda trata prompt como uma instrução que você dá ao modelo. A mudança de perspectiva que importa é perceber que contexto é o recurso escasso, e o que você injeta nele determina o teto de qualidade do que sai.
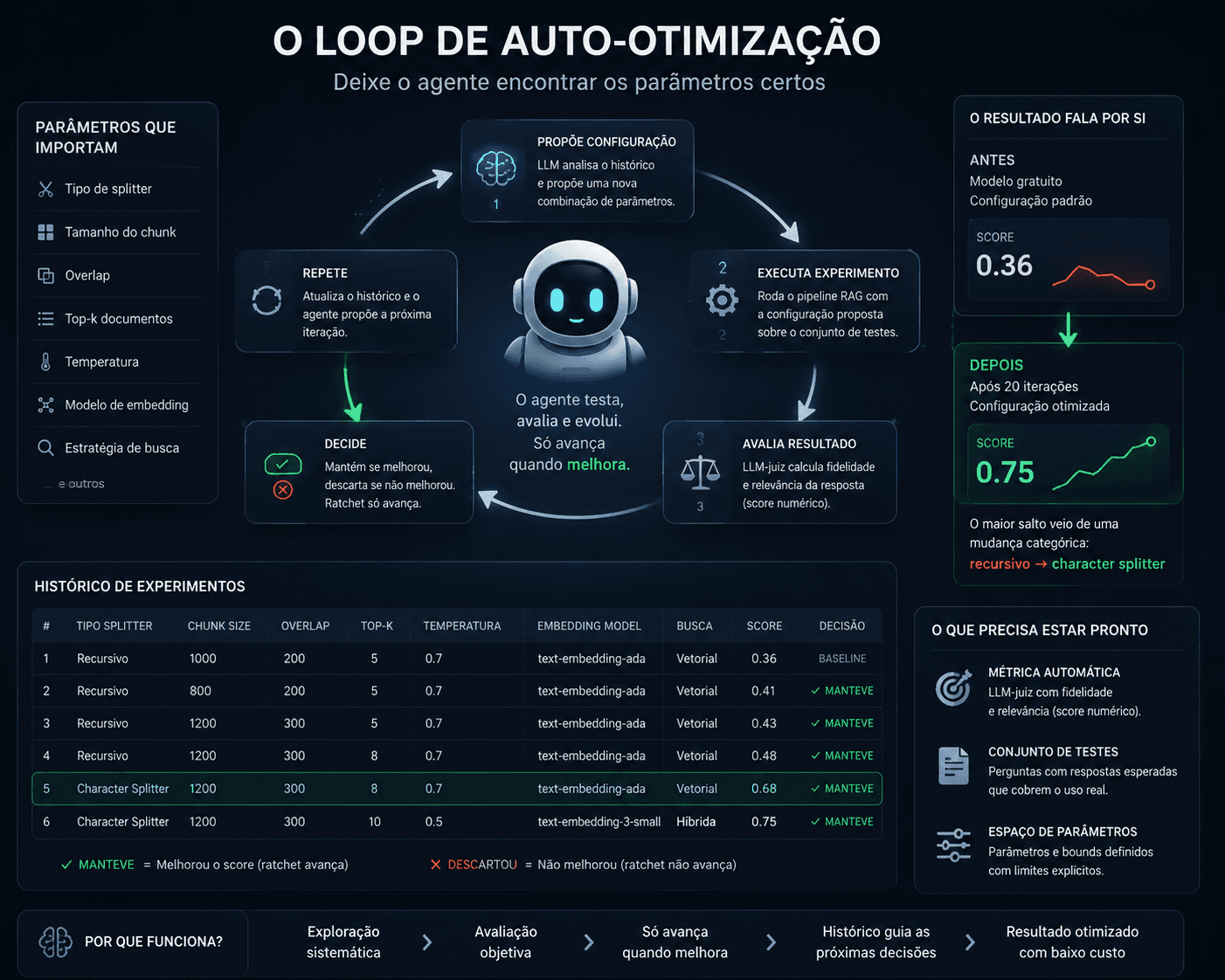
Deixar o agente encontrar os parâmetros certos: o loop de auto-otimização
Um pipeline RAG tem pelo menos meia dúzia de parâmetros que afetam a qualidade: tipo de chunking, tamanho, overlap, top-k, modelo de embedding, estratégia de busca. A maioria dos times testa esses parâmetros manualmente. Existe uma alternativa.