Deploy de LLMs em Produção: Lições Aprendidas

Deploy de LLMs em Produção: Lições Aprendidas
Colocar um LLM em produção é muito diferente de fazer um protótipo funcionar no Jupyter Notebook. Neste artigo, compartilho as lições aprendidas em projetos reais de deploy de sistemas baseados em LLMs.
Desafios Comuns
1. Latência
LLMs são inerentemente lentos. Em produção, isso se torna crítico:
- GPT-4 pode levar 10-30 segundos para respostas longas
- Usuários esperam respostas em menos de 3 segundos
Soluções:
# Streaming de respostas
async def stream_response(prompt: str):
async for chunk in llm.astream(prompt):
yield chunk.content
# Caching agressivo
from functools import lru_cache
@lru_cache(maxsize=1000)
def cached_embedding(text: str):
return embeddings.embed_query(text)2. Custos
Chamadas de API se acumulam rapidamente:
- GPT-4 Turbo: $0.01/1K tokens input, $0.03/1K tokens output
- Um sistema com 10K queries/dia pode custar $3K-10K/mês
Soluções:
- Cache de respostas similares
- Uso de modelos menores para triagem
- Batching de requests quando possível
3. Reliability
APIs externas falham. Seu sistema precisa ser resiliente:
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10)
)
async def robust_llm_call(prompt: str):
return await llm.ainvoke(prompt)Arquitetura Recomendada
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Cliente │───▶│ Gateway │───▶│ Queue │
└─────────────┘ └─────────────┘ └─────────────┘
│ │
▼ ▼
┌─────────────┐ ┌─────────────┐
│ Cache │ │ Workers │
└─────────────┘ └─────────────┘
│
▼
┌─────────────┐
│ LLM API │
└─────────────┘Monitoramento Essencial
Métricas que você precisa monitorar:
- Latência p50, p95, p99
- Taxa de erros por tipo
- Custo por request
- Token usage
- Cache hit rate
import prometheus_client as prom
llm_latency = prom.Histogram(
'llm_request_latency_seconds',
'LLM request latency',
buckets=[0.5, 1, 2, 5, 10, 30]
)
llm_tokens = prom.Counter(
'llm_tokens_total',
'Total tokens used',
['model', 'type']
)Conclusão
Deploy de LLMs em produção requer planejamento cuidadoso de arquitetura, monitoramento robusto e otimizações constantes. O protótipo é só o começo - a produção é onde o trabalho real acontece.
Assine a Newsletter
Receba conteúdo exclusivo sobre IA, LLMs e desenvolvimento em produção diretamente no seu email.
Sem spam. Cancele quando quiser.
Posts Relacionados

O que devs de IA ainda não aprenderam sobre comunicação
Chamar uma API de LLM qualquer dev consegue. Entender o problema real antes de abrir o editor é outra história. Aprendi isso numa palestra para empreendedores no Sebrae.

O gap entre ter dados e entender o que está nos dados
Antes de qualquer pipeline de AI processar dados, alguém precisa inspecioná-los. Excel quebra com volumes reais. Python resolve o volume mas exige código para cada pergunta. Existe uma camada de ferramentas que fica no meio e que faz essa inspeção ser prática.
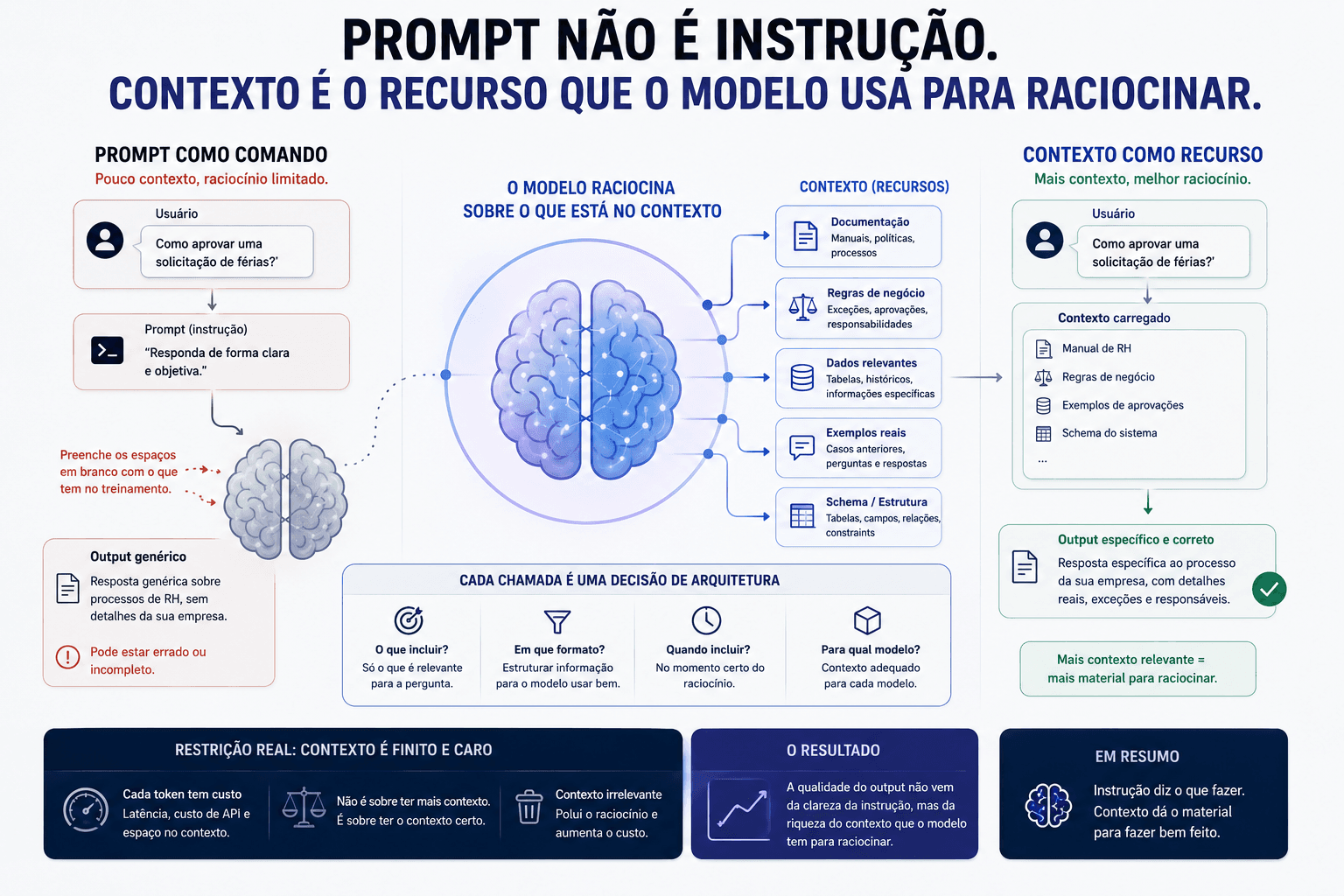
Prompt não é instrução. Contexto é o recurso que o modelo usa para raciocinar
A maioria das pessoas ainda trata prompt como uma instrução que você dá ao modelo. A mudança de perspectiva que importa é perceber que contexto é o recurso escasso, e o que você injeta nele determina o teto de qualidade do que sai.