Construindo um RAG Customizado com LangChain e Pinecone
Construindo um RAG Customizado com LangChain e Pinecone
Retrieval-Augmented Generation (RAG) é uma técnica que combina a capacidade de recuperação de informações com a geração de texto de LLMs. Neste artigo, vou mostrar como construí um sistema RAG customizado para um cliente corporativo.
O Problema
O cliente tinha uma base de conhecimento com milhares de documentos técnicos e precisava de uma forma eficiente de consultar essas informações sem depender de busca por keywords.
A Solução
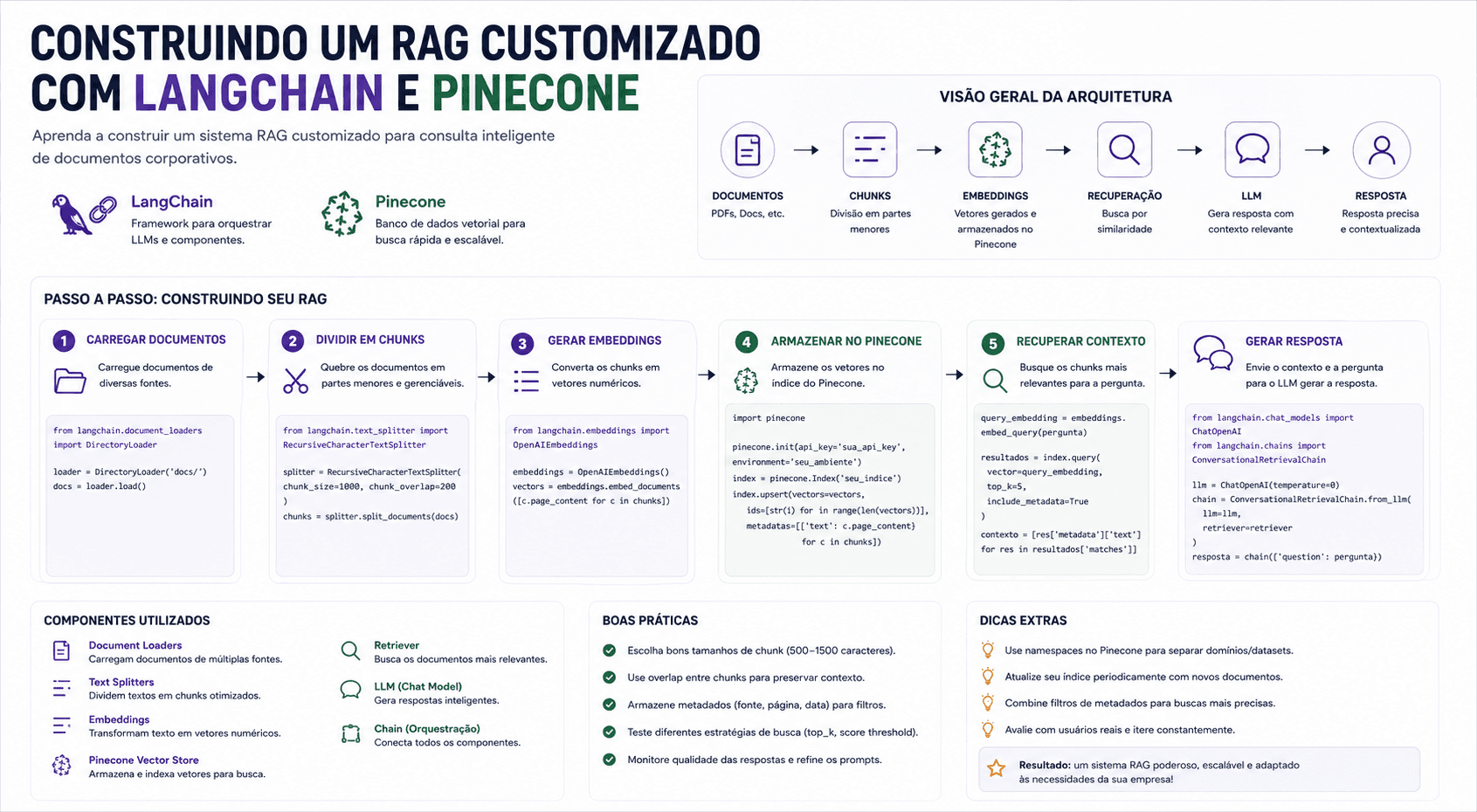
Desenvolvemos um pipeline RAG com as seguintes etapas:
1. Ingestão de Documentos
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = DirectoryLoader('./docs', glob="**/*.pdf")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
chunks = text_splitter.split_documents(documents)2. Geração de Embeddings
Utilizamos o modelo text-embedding-ada-002 da OpenAI para gerar embeddings de alta qualidade:
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
vectorstore = Pinecone.from_documents(
chunks,
embeddings,
index_name="documents"
)3. Retrieval e Geração
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4-turbo", temperature=0.1)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(
search_kwargs={"k": 4}
)
)Otimizações Implementadas
- Chunking Semântico: Dividimos documentos respeitando a estrutura (títulos, parágrafos)
- Metadata Enrichment: Adicionamos metadata aos chunks para filtros
- Hybrid Search: Combinamos busca vetorial com BM25
- Caching: Implementamos cache de queries frequentes
Resultados
- 95% de precisão nas respostas
- Tempo médio de resposta de 2 segundos
- Redução de 40% no tempo de busca de informações
Conclusão
RAG é uma técnica poderosa que permite criar sistemas de Q&A sobre bases de conhecimento corporativas. A chave está na qualidade do chunking e na escolha adequada do modelo de embeddings.
No próximo artigo, vou mostrar como implementamos reranking para melhorar ainda mais a precisão.
Assine a Newsletter
Receba conteúdo exclusivo sobre IA, LLMs e desenvolvimento em produção diretamente no seu email.
Sem spam. Cancele quando quiser.
Posts Relacionados

O que devs de IA ainda não aprenderam sobre comunicação
Chamar uma API de LLM qualquer dev consegue. Entender o problema real antes de abrir o editor é outra história. Aprendi isso numa palestra para empreendedores no Sebrae.

O gap entre ter dados e entender o que está nos dados
Antes de qualquer pipeline de AI processar dados, alguém precisa inspecioná-los. Excel quebra com volumes reais. Python resolve o volume mas exige código para cada pergunta. Existe uma camada de ferramentas que fica no meio e que faz essa inspeção ser prática.
Prompt não é instrução. Contexto é o recurso que o modelo usa para raciocinar
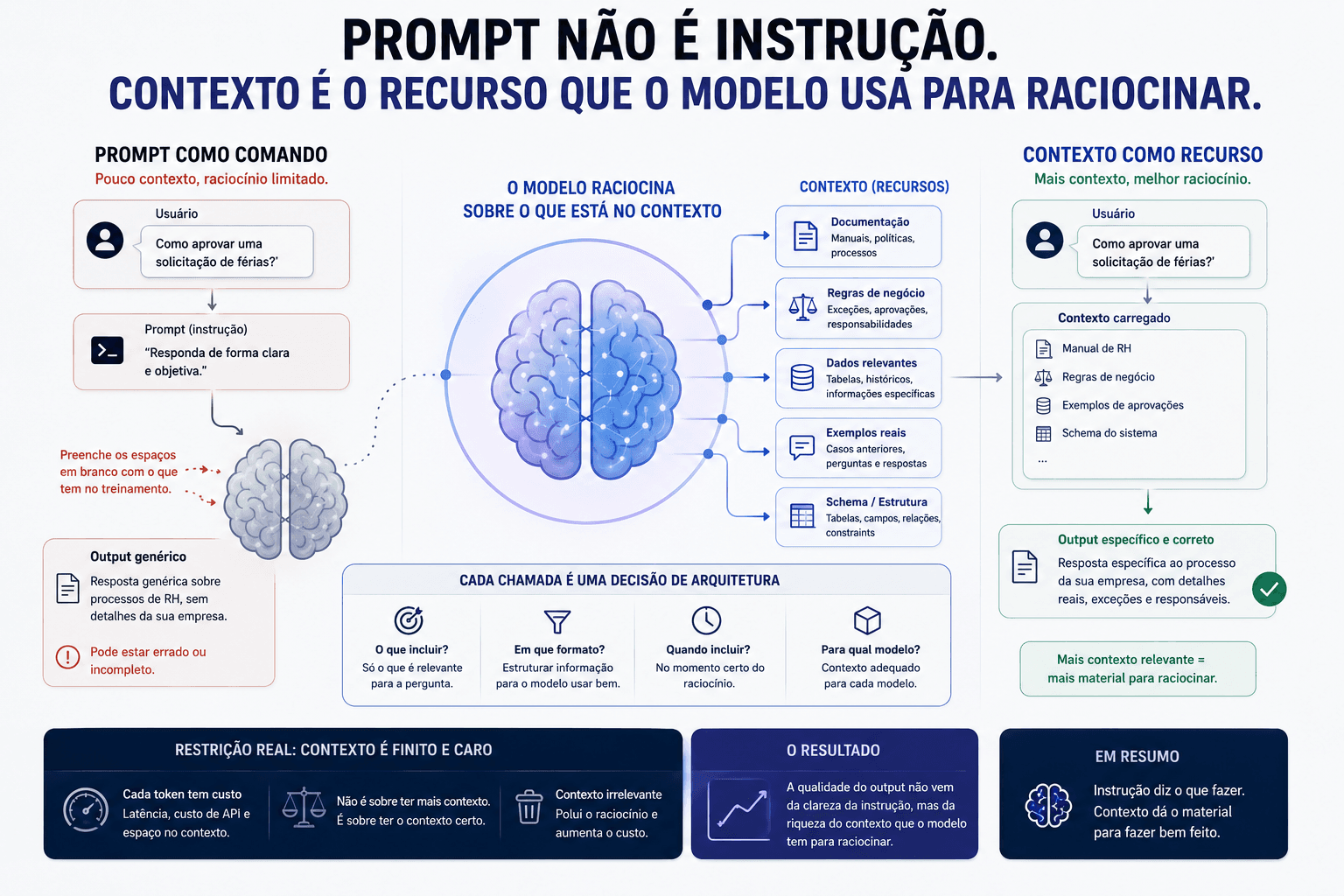
A maioria das pessoas ainda trata prompt como uma instrução que você dá ao modelo. A mudança de perspectiva que importa é perceber que contexto é o recurso escasso, e o que você injeta nele determina o teto de qualidade do que sai.